介绍六个特性:overriding,const_iterator,noexcept,constexpr,const线程安全,类的特殊成员函数。
Item 12:Declare overriding functions override.
在派生和继承中,常常涉及虚函数的使用。
C++多态(polymorphism)是通过虚函数来实现的,虚函数允许子类重新定义成员函数,而子类重新定义父类的做法称为覆盖(override),或者称为重写。
然而虚函数能够重写的条件很苛刻,他需要满足很多条件,我们编程时很容易搞错。他需要满足以下要求:
- 基类函数必须是
virtual - 基类和派生类函数名必须完全一样
- 基类和派生类函数参数必须完全一样
- 基类和派生类函数常量性(constness)必须完全一样
- 基类和派生类函数的返回值和异常说明(exception specifications)必须兼容
- 基类和派生类函数的引用限定符(reference qualifiers)必须完全一样。
下面的代码展示了这些错误:
class Base {
public:
virtual void mf1() const;
virtual void mf2(int x);
virtual void mf3() &;
void mf4() const;
};
class Derived: public Base {
public:
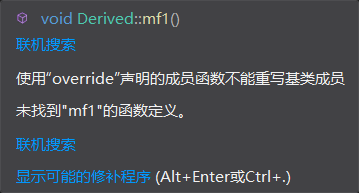
virtual void mf1();
virtual void mf2(unsigned int x);
virtual void mf3() &&;
void mf4() const;
};
最可气的是,编译器根本不会报错,最多只是给个warning,但编译时根本不会重写,所以我们需要将它显式声明为override。
class Base {
public:
virtual void mf1() const;
virtual void mf2(int x);
virtual void mf3() &;
virtual void mf4() const;
};
class Derived: public Base {
public:
virtual void mf1() const override;
virtual void mf2(int x) override;
virtual void mf3() & override;
void mf4() const override; // 可以添加virtual,但不是必要
};
比起让编译器通过warnings告诉你重写实际不会重写,不如给你的派生类成员函数全都加上override。
Item 13:Prefer const_iterators to iterators.
在STL中const_iterator等价于常量指针,他们指向不能被修改的值。C98中支持得不是很好,而在11中:const_iterator即容易获取又容易使用。容器的成员函数cbegin和cend产出const_iterator
std::vector<int> values{1,2,3,4};
auto ci = std::find(values.cbegin(), values.cend(), 3);
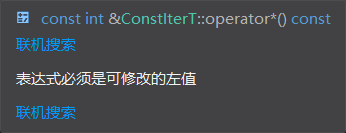
*ci = 10; //error
这其中,ci就直接被划定为const_iterator,所以就不能做修改
Item 14:Declare functions noexcept if they won’t emit exceptions.
在C++中人们认为异常信息最有用的在于:一个函数是否会抛出异常,这是一个二元性判断,即会和不会。就其本身而言,函数是否为noexcept和成员函数是否const一样重要。这个可以影响到调用代码的异常安全性和效率。原因如下:
1)避免运行时栈展开
C++98和11有不同的不抛出异常声明方式:
int f(int x) throw(); // C++98风格
int f(int x) noexcept; // C++11风格
他们最大的不同在于:在C++98的异常说明中,调用栈会展开至f的调用者,一些不合适的动作比如程序终止也会发生。C++11异常说明的运行时行为明显不同:调用栈只是可能在程序终止前展开。一个必然一个可能,这两者会对代码生成产生巨大的影响。在一个noexcept函数中,当异常传播到函数外,优化器不需要保证运行时栈的可展开状态,也不需要保证noexcept函数中的对象按照构造的反序析构。而throw()标注的异常声明缺少这样的优化灵活性,它和没加一样。
RetType function(params) noexcept; // 极尽所能优化
RetType function(params) throw(); // 较少优化
RetType function(params); // 较少优化
(2)保证移动语义能充分发挥作用
当新元素添加到std::vector,std::vector可能没地方放它,这时候,std::vector会分配一片的新的大块内存用于存放,然后将元素从已经存在的内存移动到新内存。在C++98中,移动是通过复制老内存区的每一个元素到新内存区完成的,然后老内存区的每个元素发生析构。
这种方法使得push_back可以提供很强的异常安全保证:如果在复制元素期间抛出异常,std::vector状态保持不变,因为老内存元素析构必须建立在它们已经成功复制到新内存的前提下。
在C++11中,一个很自然的优化就是将上述复制操作替换为移动操作。但是很不幸,破坏了push_back的异常安全。如果异常在移动中抛出,那么push_back操作就不能完成。但是原始的std::vector已经被修改。
因此容器们演化出了一种策略:如果可以就移动,如果必要则复制,比如说std::vector::push_back,std::vector::reverse,std:;deque::insert等等。而判断可不可以移动的关键就在于,移动中是否可能产生异常!如何判断?检查是否声明noexcept
那么哪些函数可以写为noexcept呢?
具体来说,移动操作和swap可以写为不抛出异常,有助于程序优化。宽泛点来说,我们需要讨论宽泛契约(wild contracts)和严格契约(narrow contracts)函数
有宽泛契约的函数没有前置条件。这种函数不管程序状态如何都能调用,它对调用者传来的实参不设约束。反之,没有宽泛契约的函数就有严格契约。对于这些函数,如果违反前置条件,结果将会是未定义的。
假如现在有一个函数,我想在里面加一个前置条件冲突检查s.size()<32,那么我就不能声明为noexcept,我需要在里面写一个异常抛出函数,抛出"precondition was violated"异常。
void f(const std::string& s) noexcept;
Item 15:Use constexpr whenever possible.
const是一个古老的关键词,他从C++诞生之日就存在,在漫长的岁月中它承担了很多很多功能,在11中,人们觉得const干太多活,让它太难顶了,于是搞了一个constexpr来帮他分担一些工作,并且使得一些功能更加明确。
总的来说constexpr就是指编译期可知,潜台词是:告诉编译器我可以是编译期间可知的,尽情的优化我吧。而const专门用来声明不变量,潜台词是:告诉程序员没人动得了我,放心的把我传出去;或者放心的把变量交给我,我啥也不动就瞅瞅。
(1)关于常量
这一部分比较简单,往往用于C++要求出现整数常量表达式( integral constant expression )的上下文。这类上下文包括数组大小,整数模板参数(包括std::array对象的长度),枚举量,对齐修饰符(alignas(val)),等等。
int sz; // 非constexpr变量
…
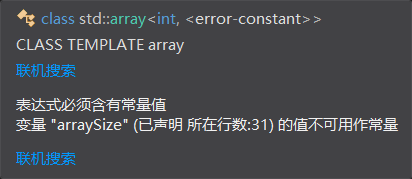
constexpr auto arraySize1 = sz; // 错误! sz的值在编译期不可知
std::array<int, sz> data1; // 错误!一样的问题
constexpr auto arraySize2 = 10; // 没问题,10是编译期可知常量
std::array<int, arraySize2> data2; // 没问题, arraySize2是constexpr
注意const不提供constexpr所能保证之事,因为const对象不需要在编译期初始化它的值。简而言之,所有constexpr对象都是const,但不是所有const对象都是constexpr。
int sz; // 和之前一样
const auto arraySize = sz; // 没问题,arraySize是sz的常量复制
std::array<int, arraySize> data; // 错误,arraySize值在编译期不可知
(2)关于函数
如果实参是编译期常量,它们将产出编译期值;如果是运行时值,它们就将产出运行时值。
如果传给constexpr函数的实参是在编译期可知的,结果就将在编译期计算完成。如果不可知,函数就不理你。
换句话说,当一个constexpr函数被一个或者多个编译期不可知值调用时,它就像普通函数一样,运行时计算它的结果。这意味着你不需要两个函数,一个用于编译期计算,一个用于运行时计算。
例子1:假如我来测量电位,把他们的结果评估为高、中、低三种情况,现在我测量了n组样本,那么得到的组合就是3^n。我们需要一个方法在编译期计算3^n。C++标准库提供了std::pow,这里还有两个问题。
- 第一,
std::pow是为浮点类型设计的 我们需要整型结果。 - 第二,
std::pow不是constexpr。因此我们需要自己来写:
constexpr int pow(int base, int exp) noexcept // C++11
return (exp == 0 ? 1 : base * pow(base, exp - 1));
constexpr int pow(int base, int exp) noexcept // C++14
{
auto result = 1;
for (int i = 0; i < exp; ++i) result *= base;
return result;
}
因为11的要求是constexpr函数的代码不超过一行语句,所以需要采用三目运算符加递归的方式,非常麻烦,所幸14中得到了解决。
例子2:构建一个点类
在C++11中,除了void外的所有内置类型可以是constexpr:
class Point {
public:
constexpr Point(double xVal = 0, double yVal = 0) noexcept : x(xVal), y(yVal){}
constexpr double xValue() const noexcept { return x; }
constexpr double yValue() const noexcept { return y; }
void setX(double newX) noexcept { x = newX; }
void setY(double newY) noexcept { y = newY; }
private:
double x, y;
};
Point的构造函数被声明为constexpr,因为如果传入的参数在编译期可知,Point的数据成员也能在编译器可知。因此Point就能被初始化为constexpr:
constexpr Point p1(9.4, 27.7); // 没问题,构造函数会在编译期“运行”
constexpr Point p2(28.8, 5.3); // 也没问题
类似的,xValue和yValu的getter函数也能是constexpr,这使得我们可以写一个constexpr函数里面调用Point的getter并初始化constexpr的对象:
constexpr Point midpoint(const Point& p1, const Point& p2) noexcept
{
return { (p1.xValue() + p2.xValue()) / 2,
(p1.yValue() + p2.yValue()) / 2 };
}
constexpr auto mid = midpoint(p1, p2);
这就很给力了,因为:
- mid对象通过调用构造函数,getter和成员函数就能在只读内存中创建!
- 你可以在模板或者需要枚举量的表达式里面使用像
mid.xValue()*10的表达式! - 以前相对严格的某一行代码只能用于编译期,某一行代码只能用于运行时的界限变得模糊,一些运行时的普通计算能并入编译时。越多这样的代码并入,你的程序就越快。(当然,编译会花费更长时间)
在14中,放开了对void的限制,现在你可以:
class Point {
public:
...
constexpr void setX(double newX) noexcept { x = newX; }
constexpr void setY(double newY) noexcept { y = newY; }
...
};
也能写这样的函数:
constexpr Point reflection(const Point& p) noexcept
{
Point result;
result.setX(-p.xValue());
result.setY(-p.yValue());
return result;
}
我们在客户端就能写:
constexpr Point p1(9.4, 27.7);
constexpr Point p2(28.8, 5.3);
constexpr auto mid = midpoint(p1, p2);
constexpr auto reflectedMid = reflection(mid);
Item 16:Make const member functions thread safe
本文解决以下问题:
- 是什么导致const成员函数变成了非线程安全
- 如何避免非线程安全问题
什么导致const成员函数变成了非线程安全?
首先const的成员函数的线程是绝对安全的,因为它不允许对类的成员变量进行修改操作,只能读取。让它变得不安全的是mutable关键词
mutable只能用来修饰类的数据成员;而被mutable修饰的数据成员,可以在const成员函数中修改。
下面这段代码展示了mutable的作用和为什么线程不安全。roots本身是一个const成员函数,每次返回rootVals,而这个值只有在第一次的时候才需要计算,此后只需要直接返回即可,所以这就有了一个rootsAreValid来表明这个值是否是已经计算。
此时如果有两个线程同时执行roots,第一个线程发现rootsAreValid是false,开始计算rootVals,在计算的过程中,第二个线程开始执行,发现rootsAreValid也是false,也开始计算rootvals,这就会出错。
class Polynomial {
public:
using RootsType = std::vector<double>;
RootsType roots() const {
if (!rootsAreValid) {
....
rootsAreValid = true
}
return rootVals;
}
private:
mutable bool rootsAreValid { false };
mutable RootsType rootVals{};
};
如何避免这个问题?
(1)使用互斥锁
class Polynomial {
public:
using RootsType = std::vector<double>;
RootsType roots() const
{
std::lock_guard<std::mutex> g(m); // lock mutex
if (!rootsAreVaild) { // 如果缓存无效
rootsAreVaild = true;
}
return rootsVals;
} // unlock mutex
private:
mutable std::mutex m;
mutable bool rootsAreVaild { false };
mutable RootsType rootsVals {};
};
上面的代码中引入了一个mutable的mutex,因为加锁和解锁本身是会对mutex本身有改动,所以是mutable,但这就带来两个问题:
- 开销变大了,后面每次都要加锁获取
rootVals,但是其实只有第一次是可读可写的,非线程安全的,后面就变成只读的了是线程安全的 mutex本身其实是一个只具备移动语义的类,这导致Polynomial类相应也变成了只具备移动语义的类了,限制了Polynomial类的使用范围。
(2)使用原子变量
class Point { // 2D point
public:
double distanceFromOrigin() const noexcept
{
++callCount; // 原子的递增
return std::sqrt((x * x) + (y * y));
}
private:
mutable std::atomic<unsigned> callCount{ 0 };
double x, y;
};
使用atomic确保修饰的counter,保证其他线程视这个操作为不可分割的。与std::mutex一样,std::atomic是move-only类型,所以在Point中调用Count的意思就是Point也是move-only的。因为对std::atomic变量的操作通常比互斥量的获取和释放的消耗更小,所以可能更倾向与依赖std::atomic。但他也有一个很大的问题:
下面的代码的问题是:
- 一个线程调用
Widget::magicValue,将cacheValid视为false,执行这两个昂贵的计算,并将它们的和分配给cachedValue。 - 此时,第二个线程调用
Widget::magicValue,也将cacheValid视为false,因此执行刚才完成的第一个线程相同的计算。
class Widget {
public:
int magicValue() const
{
if (cacheVaild) return cachedValue;
else {
auto val1 = expensiveComputation1();
auto val2 = expensiveComputation2();
cachedValue = val1 + val2; // 第一步
cacheVaild = true; // 第二步
return cachedVaild;
}
}
private:
mutable std::atomic<bool> cacheVaild{ false };
mutable std::atomic<int> cachedValue;
};
所以原子操作只适合于单变量的情况,如果是多变量或多内存位置应使用互斥锁。
Item 17:Understand special member function generation
在C++术语中,特殊成员函数是指C++自己生成的函数。C++98有四个:默认构造函数函数,析构函数,拷贝构造函数,拷贝赋值运算符。这些函数仅在需要的时候才生成。
- class没有任何的
constructor,但它内含member object,而后者有默认的构造函数。 - class没有任何的
constructor,但是它派生自一个带有默认构造函数的基类。 - 带有虚函数的类
- 继承自带有虚函数的基类
只有在满足上述情况下,编译期才会帮我们生成默认的构造函数,帮我们调用成员变量的构造函数进行初始化,或者是创建虚函数表,调用基类的构造函数,初始化基类等工作。下面的代码就不会产生默认构造函数。
class simple {
private:
int data;
};
除此以外,11还产生了两个新的特殊成员函数:移动构造函数,移动赋值操作符,其声明方式如下:
class Widget {
public:
.....
Widget(Widget&& rhs);
Widget& operator=(widget&& rhs);
};
移动构造函数的生成规则类似于拷贝构造函数,仅仅当编译器需要的时候才会生成,要求其每一个非static的成员都具有移动语义。下面给出一个例子,Private类型不具有移动语义:
class test {
public:
test() {
p = new char('a');
}
test(const test& other) {
std::cout << "copy construct" << std::endl;
}
private:
char* p = nullptr;
};
int main() {
test t;
test c(std::move(t));
return 0;
}
分析:当执行test t时,调用默认构造函数,将p赋值为a。执行test c(std::move(t));时,由于成员不具有移动语义,所以并不能移动构造,只能调用拷贝构造函数,输出"copy construct",同时p也没有赋值,依然是nullptr。

因此当我们将成员变量改为公有类型,去掉拷贝构造函数,就能使这个类具有移动语义特性时,它就能正确执行:
class test {
public:
test() {
str = "test";
}
std::string str;
};
int main() {
test t;
test c(std::move(t));
return 0;
}
如果给上面的代码加一个拷贝构造函数:
test(const test& other) {
std::cout << "copy construct" << std::endl;
}
结果会调用拷贝构造函数,而不是使用移动构造。所以我们可以总结得到,造成不能移动构造的罪魁祸首是test(const test& other)和char* p = nullptr;
那么为什么会这样呢?6个特殊函数的关系如何呢?
- 默认构造函数,在用户没有声明自定义的构造函数的时候并且编译期需要的时候生成
- 默认析构函数,销毁对象时,没有自定义的析构函数就会生成
- 拷贝构造函数和拷贝赋值操作符,用户自定义了移动操作会导致不生成默认的拷贝构造函数,其他和上面写的C98的四条原则一样
- 移动构造函数和移动赋值操作符,仅仅在没有用户自定义的拷贝操作,移动操作和析构操作的时候才会生成
那么如何在自定义能有效使用默认移动构造函数呢?使用default
class test {
public:
test() {
str = "test";
}
test(const test& other) {
std::cout << "copy construct" << std::endl;
}
test(test&&) = default; //显示的声明默认的移动构造函数
test& operator=(test&&) = default;
std::string str;
};