描述了三大智能指针:unique_ptr, shared_ptr, weak_ptr,介绍了为什么更倾向于用make构造而不是new,如何构建Pimpl来减轻编译负担。
Item 18:Use unique_ptr for exclusive-ownership resource management.
先解释一下,exclusive ownership是独占所有权的意思,顾名思义这一章的主要目的是介绍如何利用unique_ptr管理独占所有权的资源。
std::unique_ptr体现了显式所有权的语义:非空的std::unique_ptr总是拥有它指向的对象,换句话说我们只能通过移动转移所有权,而不允许复制。
它的主要应用是在工厂模式。假设有一个基类和三个派生类,通过一个工厂函数来返回某个派生类的std::unique_ptr,这样调用方就不需要费心什么时候销毁返回的对象了:std::unique_ptr会负责这件事。
工厂函数使用了C++多态的特性,将存在继承关系的类,通过一个工厂类创建对应的子类(派生类)对象。比如父类是Shoes,子类有Nike,LiNing,Adidas,假设有一个工厂函数,把生产鞋子的需求输入其中,他就能调用shoes父类下面的子类进行构造。
我们做一个完整的例子,投资类下面有三个子类:股票、债券、期货,再带一个工厂函数:
#pragma once
#include <assert.h>
#include <memory>
#include <iostream>
#include <functional>
//类定义
class Investment {
public:
virtual ~Investment() {
std::cout << "investment destoryed\n";
}
};
void makeLogEntry(Investment* pInv) {
std::cout << "deleting investment on " << pInv << "\n";
}
class Stock : public Investment {
public:
Stock() {
std::cout << "make an invesetment on stock\n";
}
virtual ~Stock() {
std::cout << "a stock investment destoryed,";
}
};
class Bond : public Investment {
public:
Bond() {
std::cout << "make an investmentt on bond\n";
}
virtual ~Bond() {
std::cout << "a bond investment destroyed,";
}
};
class RealEstate : public Investment {
public:
RealEstate() {
std::cout << "make an investmentt on RealEstate\n";
}
virtual ~RealEstate() {
std::cout << "a RealEstatend investment destroyed,";
}
};
void deleteAndLog(Investment* pInv) {
makeLogEntry(pInv);
delete pInv;
}
template<typename T, typename... Ts>
static auto makeInvestment(Ts&&... params) {
auto delInvmt = [](Investment* pInv)
{
makeLogEntry(pInv);
delete pInv;
};
typedef std::unique_ptr<Investment, decltype(delInvmt)> InvestmentPtr;
std::cout << sizeof(InvestmentPtr) << "\n";
InvestmentPtr pInv(nullptr, delInvmt);
pInv.reset(new T(std::forward<Ts>(params)...));//不能直接将裸指针赋值给一个unique_ptr,要使用reset
return pInv;
}
unique_ptr默认的销毁方式是通过对unique_ptr中的裸指针进行delete操作,但是也可以在声明的时候指定销毁函数,在上面的代码中,通过lambda表达式置顶了一个打印日志函数,要在销毁指针的时候会打印日志。
auto delLog = [](int* pInv)
{
cout << "See you !" << endl;
delete pInv;
};
std::unique_ptr<int, decltype(delLog)> pInt(nullptr, delLog);
pInt.reset(new int(1));
std::cout << *pInt << "\n";
客户端的调用方法如下,这样会产生一个unique_ptr指针指向stock,只要这个程序不结束,那么他就不会调用销毁函数,反之当程序终止时调用函数销毁对象。
auto pInvestment = makeInvestment<Stock>();
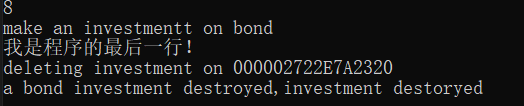
我们还可以通过move的方式转移所有权,但不能调用拷贝构造,参见delete那一章。
auto pInvestment = makeInvestment<Bond>();
auto pInvestment2 = std::move(pInvestment);
总结一下:
delInvmt是自定义的销毁器,在std::unique_ptr析构时,自定义的销毁器会来完成释放资源必需的操作。这里用lambda表达式来实现delInvmt,不仅更方便,性能还更好。- 自定义的销毁器的类型必须与
std::unique_ptr的第二个模板参数相同,因此我们要用decltype(delInvmt)来声明std::unique_ptr。 makeInvestment的基本策略是创建一个空的std::unique_ptr,再令它指向合适的类型,再返回。其中我们把delInvmt作为第二个构造参数传给std::unique_ptr,从而将销毁器与pInv关联起来。- 无法将裸指针隐式转换为
std::unique_ptr,需要用reset来修改std::unique_ptr持有的裸指针。 - 我们在创建具体的对象时,使用了
std::forward将makeInvestment的所有参数完美转发给对应的构造函数。 - 注意
delInvmt的参数是Investment*,而它的实际类型可能是派生类,因此需要基类Investment有一个虚的析构函数。
Item 19:Use shared_ptr for shared-ownership resource management.
很多语言都有GC(garbage collection)机制,但这种机制带来的是资源释放的不确定性,而原始的C语言有两种内存:栈上的内存(函数的局部变量等等,由操作系统释放),动态内存(依靠new,malloc等方式用户自己分配的内存,需要手动释放)。如果我们在程序中忘了释放这些动态内存,而程序又是会持续运行的服务进程,会导致内存占用越来越高,轻者致残影响系统性能,重者致命导致进程崩溃。下面举个例子:
下面这一段程序按照规范合理释放内存,他的内存使用情况如下
for (int i = 0; i < 10000; i++) {
int* p = (int*)malloc(sizeof(int));
*p = i;
cout << *p << endl;
free(p);
}
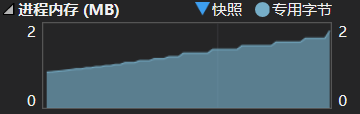
然而如果我去掉了free(p)这一句,就会导致如下的情况,问题一目了然!有可能你的程序从70MB跑了一年跑到200MB了。
以上介绍了不及时释放内存导致泄露的结果,下面就正式介绍C++是如何在保证手工管理内存的确定性和自动GC机制的便利性中做平衡的。现代CPP给出的方案是shared_ptr!
从c++11开始引入的shared_ptr,用来表示指针对指向对象的“共享所有权”;一个对象可以被多个shared_ptr指向和访问,这些shared_ptr类型的指针共同享有该对象的所有权,当最后一个指向该对象的shared_ptr生命周期结束的时候,对象被销毁。
下面介绍他的机制和特点:
(1)基于引用计数实现
他的机制和JVM的机制一样,基于引用计数实现,shared_ptr的构造将引用计数加1,销毁的时候引用计数减1,而赋值则将源指针引用计数加1,目标指针引用计数减1,例如P1=P2,P1指向对象的引用计数减1,P2指向对象的引用计数加1。当引用计数减1之后为0的时候,shared_ptr将会销毁指向的对象。shared_ptr的构造函数函数会增加引用计数,但是移动构造除外,因为移动构造并没有增加指向对象的引用计数,所以不需要改变引用计数;需要注意:
std::shared_ptr占用的内存空间是原生指针的两倍- 被指向对象的内存空间必须是动态分配的
- 增加或者减少指针引用对象的操作必须是原子操作类型的,多线程操作时要谨慎使用
std::shared_ptr
(2)销毁器不是指针类型的一部分
与unique_ptr类似,shared_ptr同样也支持自定义销毁方法(默认是直接调用delete),与unique_ptr不同的是,销毁方式是unique_ptr类型的一部分,而shared_ptr的销毁方式却不是。
auto loggingDel = [](Widget *pw)
{
makeLogEntry(pw);
delete pw;
};
std::unique_ptr<Widget, decltype(loggingDel)> upw(new Widget, loggingDel);
std::shared_ptr<Widget> spw(new Widget, loggingDel);
不把销毁方式作为shared_ptr类型的一部分可以带来更大的灵活性,因为这里不同的shared_ptr指针对象可能需要不同的销毁方式:
auto customDeleter1 = [](Widget *pw) { … }; // custom deleters,
auto customDeleter2 = [](Widget *pw) { … }; // each with adifferent type
std::shared_ptr<Widget> pw1(new Widget, customDeleter1);
std::shared_ptr<Widget> pw2(new Widget, customDeleter2);
//由于有相同的结构,所以可以写成
std::vector<std::shared_ptr<Widget>>vpw{pw1, pw2};
(3)包含一个控制块
与unique_ptr不同的是,自定义销毁方式并不会改变shared_ptr的size,shared_ptr的size始终是两倍的裸指针size,其内存布局是如下图所示:
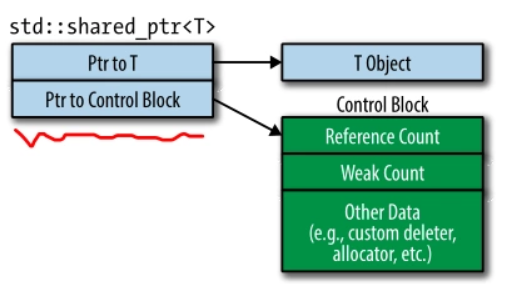
- 使用
std::make_shared的时候总是分配控制块 shared_ptr由unique_ptr或裸指针构建时分配控制块shared_ptr由其他shared_ptr或weak_ptr构建时不分配新的控制块,而是沿用既有智能指针的控制块
这就会带来一个问题,当我们用一个裸指针构建多个shared_ptr时,会分配多个控制块,同一个对象确有多个引用计数(控制块),这就很容易导致一个对象被销毁多次,下面的代码描述了这种情况:
auto pw = new Widget; // pw 是原生指针
//…
std::shared_ptr<Widget> spw1(pw, loggingDel); // create control block for *pw
std::shared_ptr<Widget> spw2(pw, loggingDel); // create 2nd control block
如何避免这个问题呢?尽可能避免使用裸指针来构建shared_ptr,使用make_shared。
关于shared_ptr性能的讨论
shared_ptr的控制块是动态生成的,尽管占用的空间并不大,但是控制块的实际实现比想象的要复杂,实现控制块使用到了继承和虚函数,同时引用计数的增减是原子操作也增加了性能上的代价,这些都导致了shared_ptr并不是管理所有动态资源的最好方案,使用shared_ptr解引用获取对象时会比直接使用裸指针的代价更高;
然而,尽管shared_ptr有在性能上付出了一定的代价,其带来的收益是非常显著的,shared_ptr解决了动态分配资源的生命周期自动管理,大多数时候,在“共享所有权”的语义下,使用shared_ptr管理动态资源都是值得推荐的;而没有“共享所有权”语义的其他情况下,例如“独占所有权”,则可以使用unique_ptr来代替;
另一个shared_ptr不能做的事情是管理数组,不能使用std::shared_ptr这样的类型,然而,c++ 11之后标准库已经引入了std::array,shared_ptr管理一个std::array类型的对象是可行的。
Item 20:Use weak_ptr for shared_ptr-like pointers that can dangle.
虽然有了std::shared_ptr,但我们却并不知道指向的资源到底有没有被销毁,我们希望有一种智能指针能够追踪他什么时候空悬(dangle,即对象不存在),解决方案就是采用std::weak_ptr。
先,这个指针并不是单独存在的,他需要搭配shared_ptr一起使用。std::weak_ptr通常是由std::shared_ptr中创建而来。它们指向的地方与初始化它们的std::shared_ptr指向的地方相同,但它们不会影响指向对象的引用计数:
auto spw = std::make_shared<Widget>(); // spw是std::shared_ptr<Widget>
// 引用计数为1
...
std::weak_ptr<Widget> wpw(spw); // wpw指向spw指向的Widget,引用计数仍然为1
...
spw = nullptr; // 引用计数变成0,Widget被销毁,wpw现在变成空悬指针
如上所示,当weak_ptr变为空悬指针时,我们可以去检查它if (wpw.expired())
不过一般状况是:当你去检查std::weak_ptr是否过期,如果没有过期(即不是空悬),就要取得它指向的对象。
因为std::weak_ptr没有解引用操作,所以没有办法写出解引用的代码。就算有这个操作,单独的检查操作和解引用操作会引出一个竞争条件:在调用检查操作和解引用操作之间,另一个线程重赋值或销毁最后一个指向对象的std::shared_ptr,因此导致对象被销毁,这样解引用就产生了未定义行为。
因此需要原子操作来检查shared_ptr是否过期,通常情况我们使用std::weak_ptr::lock,如果不为空则返回对应的shared_ptr否则返回nullptr
(1)应用一:cache缓存
下面是一个使用weak_ptr和哈希表容器构建缓存的示例,由于loadWidget的操作可能是大开销函数,所以我们最好设计一个缓存,保存我们加载过的对象。
std::shared_ptr<const Widget> fastLoadWidget(WidgetID id)
{
static std::unordered_map<WidgetID, std::weak_ptr<const Widget>> cache;
auto objPtr = cache[id].lock(); // objPtr是指向缓存对象的shared_ptr(否则为空)
if (!objPtr) { // 如果不在缓存中
objPtr = loadWidget(id); // 大开销函数加载它
cache[id] = objPtr; // 缓存它
}
return objPtr;
}
在局部变量前,加上关键字static,该变量就被定义成为一个静态局部变量。
- 该变量在全局数据区分配内存;
- 静态局部变量在程序执行到该对象的声明处时被首次初始化,即以后的函数调用不再进行初始化;
- 静态局部变量一般在声明处初始化,如果没有显式初始化,会被程序自动初始化为0;
- 其作用域为局部作用域
(2)应用二:观察者模式
这个设计模式的主要组成是subject(主题,即状态可能改变的对象)和observer(观察者,即出现状态改变时被通知的对象)。

B是主题,AC为观察者,AC对B有共同使用权,他们都有指向B的shared_ptr用于接收B的改变。现在的问题是如果B要及时知道A是否被销毁,问号处应该使用什么指针?有三种选择:
- 原生指针。若A被销毁,则B指向A的指针会空悬,B没有能力发现,B去解指针的引用时会发生未定义行为!
shared_ptr。A指向B且B指向A,形成循环。他们两抱团取暖,互相引用计数,形成闭环,即使其他数据不再指向AB,他们依然不会被销毁。从另一个角度来说,AB已经泄露:程序不能使用它们,资源无法回收。weak_ptr。很好的解决了问题!尽管A和B在互指,B的指针也不会影响A对象的引用计数。如果A被销毁了,B的指针能知道它已经过期了。
Item 21:Prefer std::make_unique and std::make_shared to direct use of new
为什么用make比用new好?直接上结论:
(1)不用重复类型
auto upw1(std::make_unique<Widget>());
std::unique_ptr<Widget> upw2(new Widget);
上述代码通过make,我们只用写一遍widget,如果连续重复类型,有可能会导致dump
(2)异常安全
假设我们有这样的两个函数
void processWidget(std::shared_ptr<Widget> spw, int priority);
int computePriority();
processWidget(std::shared_ptr<Widget>(new Widget), computePriority()); // potential resource leak!
在processWidget的参数求值过程中,我们只能确定下面几点:
new Widget一定会执行,即一定会有一个Widget对象在堆上被创建。std::shared_ptr的构造函数一定会执行。computePriority一定会执行。
new Widget的结果是std::shared_ptr构造函数的参数,因此前者一定早于后者执行。除此之外,编译器不保证其它操作的顺序,即有可能执行顺序为:
new Widget- 执行
computePriority - 构造
std::shared_ptr
如果第2步抛异常,第1步创建的对象还没有被std::shared_ptr管理,就会发生内存泄漏。如果这里我们用std::make_shared,就能保证new Widget和std::shared_ptr是一起完成的,中间不会有其它操作插进来,即不会有不受智能指针保护的裸指针出现:
processWidget(std::make_shared<Widget>(), computePriority()); // no potential resource leak
(3)更高效
std:shared_ptr<Widget> spw(new Widget);
这行代码中,我们以为只有一次内存分配,实际发生了两次,第二次是在分配std::shared_ptr控制块。如果用std::make_shared,它会把Widget对象和控制块合并为一次内存分配。
但他也存在一些问题:
- 无法传入自定义的销毁器。
- make函数初始化时使用了括号初始化,而不是花括号初始化,比如
std::make_unique>(10, 20)创建了一个有着20个值为10的元素的vector,而不是创建了{10, 20}这么两个元素的vector - 对象和控制块分配在一块内存上,减少了内存分配的次数,但也导致对象和控制块占用的内存也要一次回收掉。即,如果还有
std::weak_ptr存在,控制块就要在,对象占用的内存也没办法回收。如果对象比较大,且std::weak_ptr在对象析构后还可能长期存在,那么这种开销是不可忽视的。
如果我们因为前面这三个缺点而不能使用std::make_shared,那么我们要保证,智能指针的构造一定要单独一个语句。回到之前processWidget的例子中,假设我们有个自定义的销毁器void cusDel(Widget* ptr);,因此不能使用std::make_shared,那么我们要这么写来保证异常安全性:
std::shared_ptr<Widget> spw(new Widget, cusDel);
processWidget(spw, computePriority());
当然我们还可以加上移动语义,让它更高效:
std::shared_ptr<Widget> spw(new Widget, cusDel);
processWidget(std::move(spw), computePriority());
Item 22:When using the Pimpl Idiom, define special member functions in the implementation file.
什么是Pimpl?
Pimpl(Pointer to implementation)特别用于减轻编译负担,这是一个C++编程的小技巧,通过它你能将一个类的数据成员打包放进一个具体的实现类或者结构体中,这些数据成员的访问能将通过指针间接访问。举个例子
class Widget() //定义在头文件`widget.h`
{
public:
Widget();
...
private:
std::string name;
std::vector<double> data;
Gadget g1, g2, g3; //Gadget是用户自定义的类型
}
当我们改变Gadget类的时候,整个程序都需要重新编译,所以我们希望改变这种现状。现在我们使用智能指针实现一个Pimpl来解决这个问题:
class Widget //在"Widget.h"中
{
public:
Widget();
...
private:
struct Impl; //声明一个 实现结构体
std::unique_ptr<Impl> pImpl; //使用智能指针而不是原始指针
}
实现文件写为:
#include "widget.h" //以下代码均在实现文件 widget.cpp里
#include "gadget.h"
#include <string>
#include <vector>
struct Widget::Impl //跟之前一样
{
std::string name;
std::vector<double> data;
Gadget g1,g2,g3;
}
Widget::Widget(): pImpl(std::make_unique<Imple>()){}
以上代码不会编译通过,因为我们没有给Widget实现自定义的析构函数,因此编译器为Widget准备了一个。这个析构函数会被放到Widget的定义体内,默认是内联的,因此会有一份实现在用户文件中。~Widget中只做一件事:析构pImpl,即析构一个std::unique_ptr。注意,我们隐藏了Impl的实现,在析构std::unique_ptr时编译器发现Impl还是个不完整类型,此时对它调用delete是危险的,因此编译器用static_cast禁止了这种行为。
解决方案就是我们自己实现一个析构函数,
// widget.h
class Widget {
public:
Widget();
~Widget();
...
private:
struct Impl
std::unique_ptr<Impl> pImpl;
};
// widget.cpp
...
Widget::Widget(): pImpl(std::make_unique<Impl>()){}
Widget::~Widget(){} = default; //参见item17
根据Item17,自定义的析构函数会阻止编译器生成移动构造函数和移动赋值函数,因此如果你想要Widget有移动的能力,就要自己实现(注意不要在这些特殊成员函数的声明后面加= default,这样会重复上面析构函数的问题:会被内联,因此在用户代码中有一份实现,遇到不完整类型):
class Widget {
public:
Widget();
~Widget();
//Widget(Widget&& rhs) = default; // right idea, wrong code!
//Widget& operator=(Widget&& rhs) = default;
Widget(Widget&& rhs) ;
Widget& operator=(Widget&& rhs) ;
...
};
接下来就是复制构造函数和复制赋值函数了。我们用std::unique_ptr是为了更好的实现Pimpl方法,这也导致了Widget无法自动生成复制函数(std::unique_ptr不支持),但这并不意味着Widget就不能支持复制了,我们还可以自己定义两个复制函数:
// widget.h
class Widget {
public:
...
Widget(const Widget& rhs);
Widget& operator=(const Widget& rhs);
...
};
// widget.cpp
Widget::Widget(const Widget& rhs)
: pImpl(nullptr) {
if (rhs.pImpl) {
pImpl = std::make_unique<Impl>(*rhs.pImpl);
}
}
Widget& Widget::operator=(const Widget& rhs) {
if (!rhs.pImpl) {
pImpl.reset();
} else if (!pImpl) {
pImpl = std::make_unique<Impl>(*rhs.pImpl);
} else {
*pImpl = *rhs.pImpl;
}
}
如果你把pImpl的类型改为std::shared_ptr,你会发现上面所有这些注意事项,都不见了。你不需要手动实现析构函数、移动函数、构造函数,程序编译仍然是好的。所以这么多东西仅仅针对unique_ptr。这种差异来自于std::unique_ptr和std::shared_ptr对自定义销毁器的支持方式不同。
对std::unique_ptr而言,销毁器的类型是unique_ptr的一部分,这让编译器有可能生成更小的运行时数据结构和更快的运行代码。 这种更高效率的后果之一就是unique_ptr指向的类型,在编译器的生成特殊成员函数被调用时(如析构函数,移动操作)时,必须已经是一个完成类型。 而对std::shared_ptr而言,销毁器的类型不是该智能指针的一部分,这让它会生成更大的运行时数据结构和稍微慢点的代码,但是当编译器生成的特殊成员函数被使用的时候,指向的对象不必是一个完成类型。
对于pImpl惯用法而言,在std::unique_ptr和std::shared_ptr的特性之间,没有一个比较好的折中。 因为对于类Widget以及Widget::Impl而言,他们是独享占有权关系,这让std::unique_ptr使用起来很合适。