1. Go的并发方式
1.1 并发与并行
首先要明确线程与进程的区别。这个问题真的是老生常谈了,在开始之前最好还是复习一遍:
对于操作系统来说,一个任务就是一个进程(Process),比如打开浏览器,使用word。而一个进程可能不只干一件事(比如word既要打字又要检查拼写),这种进程内的多个子任务就是线程(Thread)。
具体来说:
- 进程是操作系统分配资源的单位,而线程是进程的一个实体,是CPU调度和分派的基本单位。
- 线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
多进程与多线程:现代操作系统一般都是多进程的,他可以同时运行多个任务,一般来说一个CPU核对应一个进程,如果开启的进程比较多就需要使用时间片轮转进程调度算法。它的思想简单介绍如下:在操作系统的管理下,所有正在运行的进程轮流使用CPU,每个进程允许占用CPU的时间非常短(比如10毫秒),这样用户根本感觉不出来CPU是在轮流为多个进程服务,就好象所有的进程都在不间断地运行一样。
引入线程的好处:
- 在进程内创建、终止线程比创建、终止进程要快;
- 同一进程内的线程间切换比进程间的切换要快。
对于其他编程语言来说,当涉及到并发任务时:
- 其他语言:会在物理处理器上调度线程来运行
- go语言:会在逻辑处理器上调度goroutine来运行
go语言运行时默认会给每个可用的物理处理器分配一个逻辑处理器,逻辑处理器会用于执行所有被创建的goroutine。
如果创建一个goroutine 并准备运行,这个 goroutine 就会被放到调度器的全局运行队列中等待执行。排队排到时,放入逻辑处理器中执行
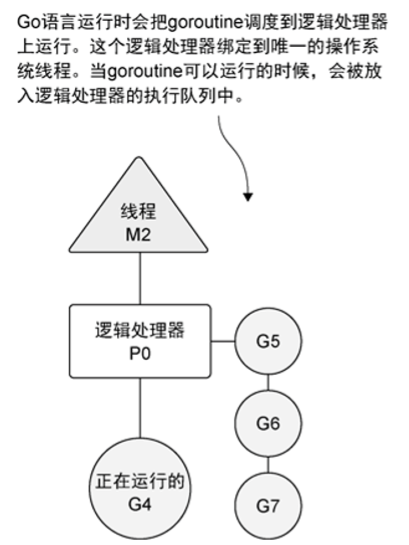
有时,正在运行的 goroutine 需要执行一个阻塞的系统调用,如打开一个文件。当这类调用发生时,线程和 goroutine 会从逻辑处理器上分离,该线程会继续阻塞,等待系统调用的返回。 与此同时,这个逻辑处理器就失去了用来运行的线程。所以,调度器会创建一个新线程,并将其绑定到该逻辑处理器上
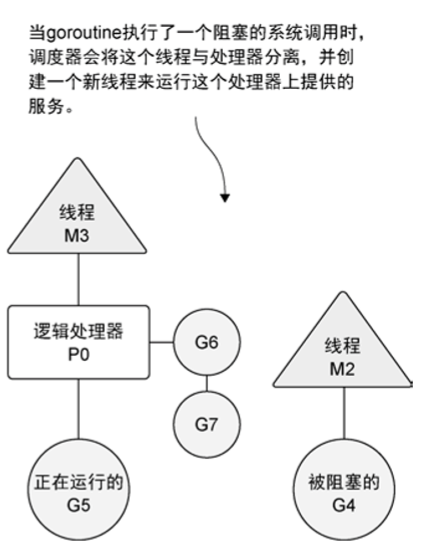
并发(concurrency)不是并行(parallelism),并行是让不同的代码片段同时在不同的物理处理器上执行。并行的关键是同时做很多事情,而并发是指同时管理很多事情。
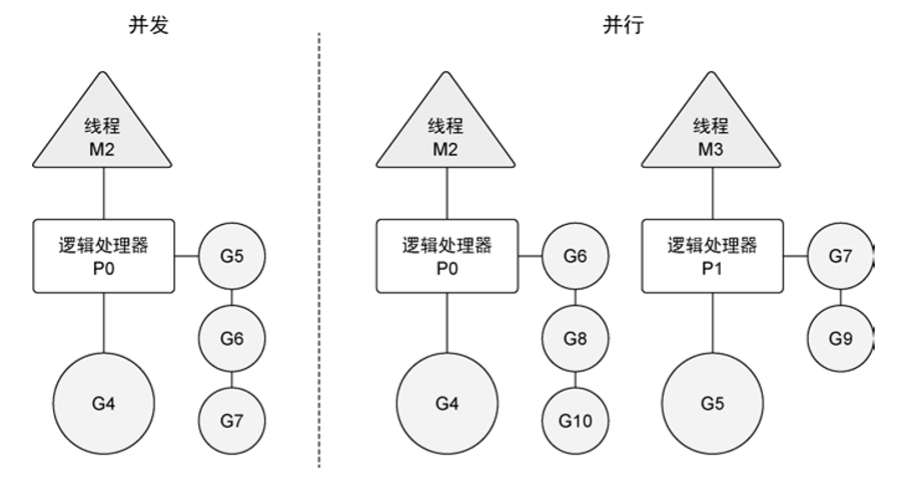
如果希望强化Go的并行能力,需要使用多个逻辑处理器,调度器会将 goroutine 平等分配到每个逻辑处理器上。当然前提是处理器有多个核心,否则无论如何也打不到真正的并行。
1.2 goroutine
下面这一套代码展示了如何用两个goroutine打印5000以内的质数:
import (
"fmt"
"runtime"
"sync"
)
// wg is used to wait for the program to finish.
var wg sync.WaitGroup
// main is the entry point for all Go programs.
func main() {
// Allocate 1 logical processors for the scheduler to use.
runtime.GOMAXPROCS(1)
// Add a count of two, one for each goroutine.
wg.Add(2)
// Create two goroutines.
fmt.Println("Create Goroutines")
go printPrime("A")
go printPrime("B")
// Wait for the goroutines to finish.
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("Terminating Program")
}
// printPrime displays prime numbers for the first 5000 numbers.
func printPrime(prefix string) {
// Schedule the call to Done to tell main we are done.
defer wg.Done()
next:
for outer := 2; outer < 5000; outer++ {
for inner := 2; inner < outer; inner++ {
if outer%inner == 0 {
continue next
}
}
fmt.Printf("%s:%d\n", prefix, outer)
}
fmt.Println("Completed", prefix)
}
首先,调用了runtime包的GOMAXPROCS函数,设定调度器可以使用的逻辑处理器数量。然后通过WaitGroup等待两个goroutine完成工作。通过go关键词,激发两个函数。在函数中使用defer关键词,保证每个goroutine一旦结束就调用Done方法。
基于调度器的内部算法,一个正运行的 goroutine 在工作结束前,可以被停止并重新调度。调度器这样做的目的是防止某个 goroutine 长时间占用逻辑处理器。
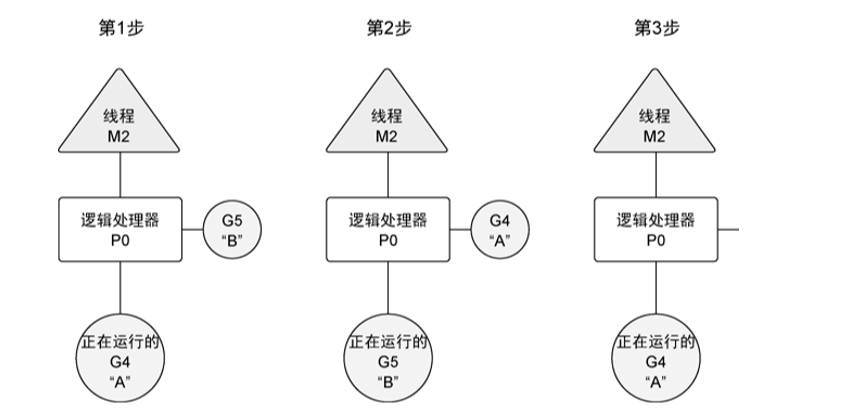
因此跟我们运行时,结果如下:
Create Goroutines
Waiting To Finish
B:2
B:3
...
B:4583 //切换至A
A:2
A:3
...
如果我们使用GOMAXPROCS函数创建了两个逻辑处理器,这会使得gorountine并行运行,结果交替输出:
Create Goroutines
Waiting To Finish
B:2
A:2
A:3
B:3
B:5
...
这是多核计算机下的运行结果,如果是单核就没有交替输出的效果。
1.3 goroutine性能
利用go自带的bench测试函数,对goroutine性能进行评估。
在main中编写如下函数,注意千万不要在其中打印print,因为性能测试会运行很多遍。
func printPrime(prefix string) {
next:
for outer := 2; outer < 1000; outer++ {
for inner := 2; inner < outer; inner++ {
if outer%inner == 0 {
continue next
}
}
}
}
func prime1(){
printPrime("Serial")
}
func prime2(){
go printPrime("Concurrency")
}
然后编写main_test.go文件:
func BenchmarkPrint1(b *testing.B) {//对顺序执行的函数进行基准测试
for i := 0; i < b.N; i++ {
prime1()
}
}
func BenchmarkGoPrint1(b *testing.B) {//对以goroutine形式执行的函数进行基准测试
for i := 0; i < b.N; i++ {
prime2()
}
}
执行命令:
go test -run x -bench . -cpu 1
输出结果如下:
BenchmarkPrint1 1701 780275 ns/op
BenchmarkGoPrint1 10000 247311 ns/op
1.4 等待goroutine
前面我们用到了等待组(Wait-Group)的机制,目的就是避免程序结束时,goroutine还没有结束。它的运作方式非常简单直接:
- 声明一个等待组;
- 使用Add方法为等待组的计数器设置值;
- 当一个goroutine完成它的工作时,使用Done方法对等待组的计数器执行减一操作;
- 调用Wait方法,该方法将一直阻塞,直到等待组计数器的值变为0。
比如:
func Prime1(wg *sync.WaitGroup){
....
wg.Done()
}
func Prime2(wg *sync.WaitGroup){
....
wg.Done()
}
func main(){
var wg sync.WaitGroup
wg.Add(2)
go Prime1(&wg)
go Prime2(&wg)
wg.Wait()
}
首先定义一个名为wg的WaitGroup变量,然后通过调用wg的Add方法将计数器的值设置成2;在此之后,程序会分别调用prime1和prime2这两个goroutine,而这两个goroutine都会在末尾对计数器的值执行减一操作。之后程序会调用等待组的Wait方法,并因此而被阻塞,这一状态将持续到两个goroutine都执行完毕并调用Done方法为止。
2. 竞争
下面的代码是一个竞争,通过Gosched函数让goroutine从当前线程退出,给其他goroutine运行的机会。
package main
import (
"fmt"
"runtime"
"sync"
)
var (
counter int
wg sync.WaitGroup
)
func main() {
wg.Add(2)
go incCounter(1)
go incCounter(2)
wg.Wait()
fmt.Println("Final Counter:", counter)
}
func incCounter(id int) {
defer wg.Done()
for count := 0; count < 2; count++ {
value := counter
runtime.Gosched() //退出
value++
counter = value
}
}
为了解决这个问题,我们可以使用竞争检测工具:
go build -race // 用竞争检测器标志来编译程序
Go_practice.exe
==================
WARNING: DATA RACE
Read at 0x00000061ad08 by goroutine 8:
main.incCounter()
D:/Go_Practice/main.go:40 +0x80
Previous write at 0x00000061ad08 by goroutine 7:
main.incCounter()
D:/Go_Practice/main.go:49 +0xa1
Goroutine 8 (running) created at:
main.main()
D:/Go_Practice/main.go:26 +0x90
Goroutine 7 (finished) created at:
main.main()
D:/Go_Practice/main.go:25 +0x6f
==================
Final Counter: 4
Found 1 data race(s)
2.1 锁
1.4.1 原子函数
原子函数能够以很底层的加锁机制来同步访问整型变量和指针。将之前不安全的代码,改为:
func incCounter(id int) {
defer wg.Done()
for count := 0; count < 2; count++ {
atomic.AddInt64(&counter, 1).
runtime.Gosched()
}
}
原子函数数会同步整型值的加法, 方法是强制同一时刻只能有一个 goroutine 运行并完成这个加法操作。另外两个有用的原子函数是LoadInt64和StoreInt64。这两个函数提供了一种安全地读 和写一个整型值的方式。
1.4.2 互斥锁
互斥锁用于在代码上创建一个临界区,保证同一时间只有一个 goroutine 可以 执行这个临界区代码。
package main
import (
"fmt"
"runtime"
"sync"
)
var (
counter int
wg sync.WaitGroup
mutex sync.Mutex
)
func main() {
wg.Add(2)
go incCounter(1)
go incCounter(2)
wg.Wait()
fmt.Printf("Final Counter: %d\n", counter)
}
func incCounter(id int) {
defer wg.Done()
for count := 0; count < 2; count++ {
mutex.Lock()
{
value := counter
runtime.Gosched()
value++
counter = value
}
mutex.Unlock()
}
}
2.2 通道
相较于上面提到的两种传统的共享机制,Go提供了通道这种数据结构,使得并发更加简单。
当一个资源需要在 goroutine 之间共享时,通道在 goroutine 之间架起了一个管道,可以通过通道共享 内置类型、命名类型、结构类型和引用类型的值或者指针。
// 无缓冲的整型通道
unbuffered := make(chan int)
// 有缓冲的字符串通道
buffered := make(chan string, 10)
使用<-一元操作符从通道中提取或发送数据:
// 有缓冲的字符串通道
buffered := make(chan string, 10)
// 通过通道发送一个字符串
buffered <- "Gopher
// 从通道接收一个字符串
value := <-buffered
(1)无缓冲的通道
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。如果两个goroutine 没有同时准备好,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。这
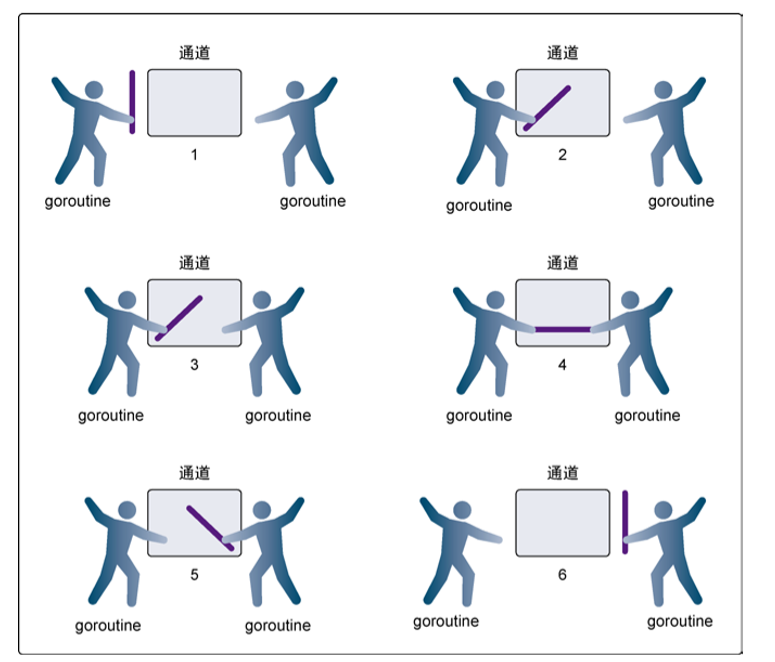
下面是模拟两个选手打网球,利用chan int传递球:
import(
"fmt"
"math/rand"
"sync"
"time"
)
var wg sync.WaitGroup
func init(){
rand.Seed(time.Now().UnixNano())
}
func main(){
court:=make(chan int)
wg.Add(2)
go player("Bob",court)
go player("Joy",court)
court <- 1
wg.Wait()
}
func player(name string,court chan int){
defer wg.Done()
for{
ball,ok:=<-court
if !ok{
fmt.Printf("Player %s Won\n", name)
return
}
n:=rand.Intn(100)
if n%13 ==0{
fmt.Printf("Player %s Missed\n", name)
close(court)
return
}
fmt.Printf("Player %s Hit %d\n", name, ball)
ball++
court<-ball
}
}
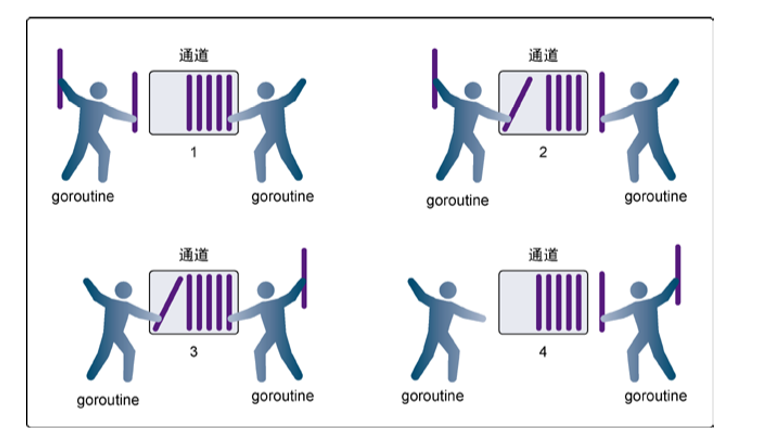
(2)有缓冲的通道
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
Select关键词
Go拥有一个特殊的关键字select,它允许用户从多个通道中选择一个通道来执行接收或者发送操作。select关键字就像是专门为通道而设的switch语句。
func callerA(c chan string) {
c <- "Hello World!"
}
func callerB(c chan string) {
c <- "Hola Mundo!"
}
func main() {
a, b := make(chan string), make(chan string)
go callerA(a)
go callerB(b)
for i:=0;i<5;i++ {
select {
case msg := <-a:
fmt.Printf("%s from A\n", msg)
case msg := <-b:
fmt.Printf("%s from B\n", msg)
//新添加的分支
default:
fmt.Println("Default")
}
}
}
运行goroutine后,会向两个通道传入字符,根据通道是否有字符,select选择性执行:
Default
Hola Mundo! from B
Hello World! from A
Default
Default
当一个goroutine取出无缓冲通道中唯一的值之后,无缓冲通道将变为空,之后任何尝试从空通道获取值的goroutine都会被阻塞并进入休眠状态。需要为select语句添加一个默认分支,让select语句在所有可选通道都已被阻塞的情况下执行默认分支即可。