1. Linux总体原理
1.1 如何理解Linux一切皆文件?
Linux访问设备的方式是通过文件访问。在windows中属于文件的东西,在linux中也是文件,在windows中不是文件的东西,比如进程磁盘socket等也被抽象为文件。
文件这个基本概念包含了两重意思:
- 在 Linux 中,一切都是字节流。意思是:文件只不过是可以读取和写入的普通字节的集合。
- 在 Linux 中,文件系统是统一的命名空间。每个文件都通过相同的API暴露出来,用户可以通过使用同一组命令操作这些设备
1.2 Linux内核中包含了哪些子系统
进程管理系统、内存管理系统、文件系统、网络系统、进程间通信系统
- 进程管理:操作每个子系统的挂起或恢复
- 内存管理:负责管理内存资源,提供虚拟内存机制
- 文件管理:隐藏了硬件的具体细节,为所有的外部设备提供了统一的操作接口(open、read、write、close)
- 网络:负责管理系统的网络设备
- 进程间通信系统:包含多种进程间通信的方法,包括:信号量、共享内存、管道等。协助多个进程间的共享资源访问,同步,消息传递等。
1.3 Linux磁盘是如何划分的
分为引导块,超级快,i节点表,文件存储区,进程交换区
- 引导块:存放引导程序,用于启动操作系统
- 超级块:存放的是文件系统本身的结构信息,比如每个区域的大小,未使用的磁盘信息等
- 文件存储区:存储文件内容
- 进程交换区: 当内存中的进程需要扩大占用的内存空间, 而当前内存空间不足时, 则把某些不常用的进程暂时替换到对换区中,在适用的时候又把他们换进内存,解决内存不足和进程之间对内存的竞争问题。
1.4 Linux内存是如何划分的?
分为:代码区、数据区、BSS区、堆区、栈区
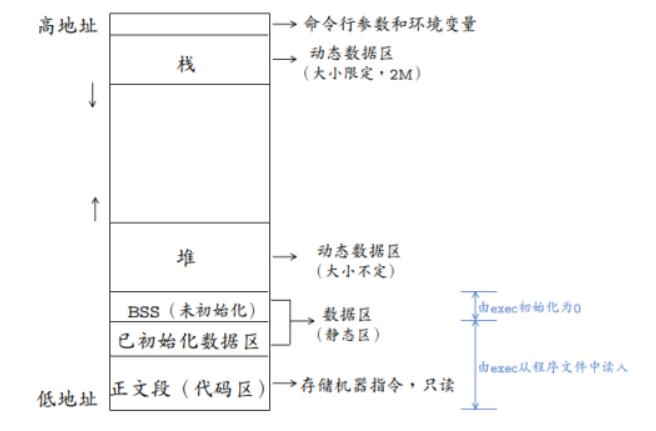
BSS区用来存放程序中未初始化的全局变量的一块内存区域。BSS是英文Block Started by Symbol的简称。
2. Linux技术细节
2.1 什么是i节点?
I的意思是index,i节点也叫索引节点。linux中,文件查找不是通过文件名称来查找的,而是通过i节点来实现的。每一个文件都有对应的inode,里面包含了与该文件有关的一些信息。
Linux查询文件位置的流程是:
- 读出这个文件的inode编号
- 根据inode编号找到inode信息
- 根据信息,读取文件数据所在的block
2.2 Linux中buffer和cache有何区别?
cache:缓存,为了弥补高速设备和低速设备交换数据的速度不匹配,引入的一个中间层,起到加快访问速度的作用。
buffer:缓冲区,目的进行流量整形,把突发的大数量小规模的 I/O 整理成平稳的小数量大规模的 I/O。比如读写时,不能来一点数据就立马读,可以等积攒到一定程度以后,一起读。
2.3 Linux开机过程是什么?
操作系统的启动可以分为:引导和启动
- BIOS上电自检,确认硬件功能正常。(BIOS:basic IO system)
- 读取引导文件,加载操作系统内核
- 运行第一个进程init
- 进入相应的运行级别(关机,单用户模式,多用户模式,图形模式,重启等等)
- 进入终端界面,输入账号密码
2.4 谈谈对fork的理解
fork函数通过系统调用创建一个(除了PID以外)与原来进程几乎完全相同的进程。拷贝的内容包括栈区、堆区、BSS区、数据区、代码区。
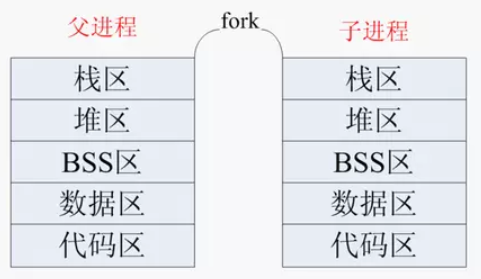
Linux下init进程是所有进程的爹 所有进程都是通过init进程fork出来的。
exec函数的作用就是:装载一个新的程序(可执行映像)覆盖当前进程内存,从而执行不同的任务。
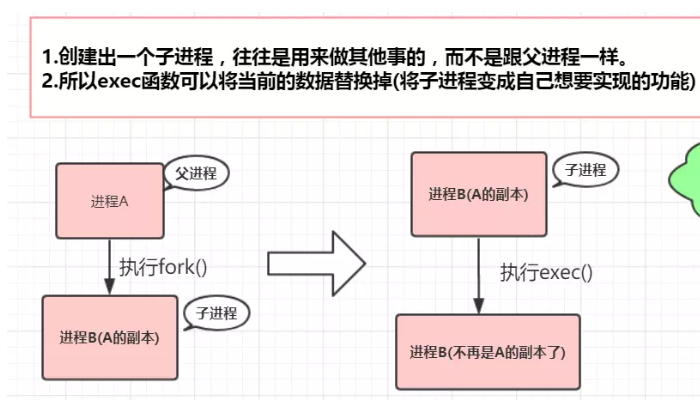
COW是写时复制的意思,由于拷贝完之后,父进程和子进程之间的数据段和堆栈是相互独立的,而如果我们想用exec来装载新的程序,复制的这些数据都是没用的。
因此COW技术允许我们,fork创建出的子进程,与父进程共享内存空间。也就是说,如果子进程不对内存空间进行写入操作的话,内存空间中的数据并不会复制给子进程。(引用而不是复制)。当父子进程有内存写入操作时才进行复制。
2.5 Malloc底层实现机制是什么?
Linux将内存划分为5大区,Linux维护一个break指针,这个指针指向堆空间的某个地址。break之前的都是已经映射好的地址,之后的是未映射的,如果访问就会出错:
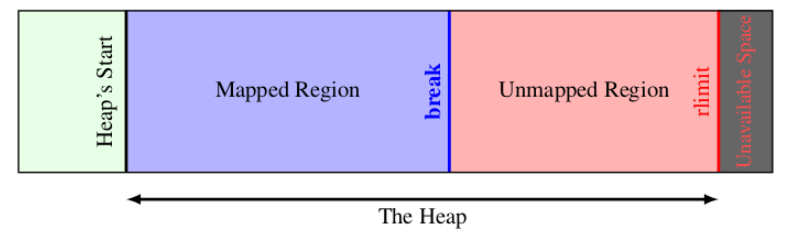
当我们调用malloc函数时,
- 它沿着连接表寻找一个大到足以满足用户请求所需要的内存块,然后将内存块一分为二(一块的大小与用户申请的大小相等,另一块的大小就是剩下来的字节)
- 一部分传给用户,一部分放回到空闲连接表上
- 用户使用free以后,释放的内存返回到空闲连接表上,空闲连接表会被切成小块
- 当用户malloc的内存过大,会阻塞,整合空闲连接表形成大块。
2.6 什么是自旋锁,如何实现?
自旋锁(spinlock):是指当一个线程在获取锁的时候,如果锁已经被其它线程获取,那么该线程将循环等待,然后不断的判断锁是否能够被成功获取,直到获取到锁才会退出循环。
互斥锁等待时会进入休眠状态,而自旋锁因为循环等待的缘故会一直活跃。
好处:减少线程切换的消耗;坏处:忙等
go实现自旋锁:
type spinLock uint32
func (sl *spinLock) Lock() {
for !atomic.CompareAndSwapUint32((*uint32)(sl), 0, 1) {
runtime.Gosched()
}
}
func (sl *spinLock) Unlock() {
atomic.StoreUint32((*uint32)(sl), 0)
}
抢到锁的gorutine会将sl从0变为1,成功跳过runtime.Gosched(),而没有抢到的则会进入循环,形成自旋。
CAS算法CompareAndSwapUint32(V,A,B)当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作。for就会卡在循环里,直到runtime.Gosched()让出CPU时间轮转片。
3. Epoll
3.1 Linux中有哪些事件处理的方式
阻塞IO:一个线程只能处理一个流的I/O事件。除非采用多线程,否则效率很低。
非阻塞忙轮询IO:即Non-Blocking Busy Polling,等待某个事件的时候,放弃其他事情,休息,专门等待,称之为阻塞。等待过程中不休息,不断询问事件是否完成,称之为非阻塞忙轮询。可以同时处理多个流,但需要从头到尾轮询,浪费资源。
Select:相当于一位代理,帮我们观察流。但这位代理只会告诉我们此刻是否有IO事件发生,我们却不知道是哪些流,只能无差别轮询。
Epoll:即event poll,不同于无差别轮询,epoll会把哪个流发生什么样的事情通知我们。
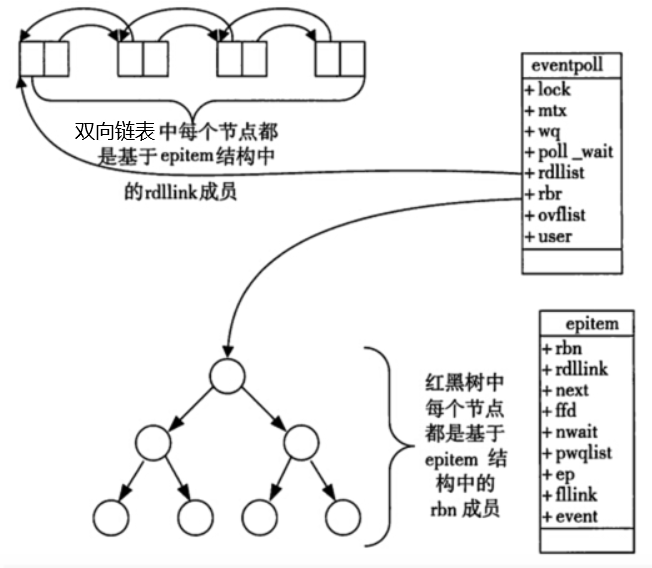
3.2 Epoll底层实现是什么?
- 红黑树的根节点,存储epoll需要监控的事件
- 双链表的头部,存储
epoll_wait返回给用户的满足条件的事件
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体:
struct eventpoll{
....
/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
struct rb_root rbr;
/*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/
struct list_head rdlist;
....
};
每次调用epoll_create方法都会创建一个epoll对象,每一个对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。在epoll中,对于每一个事件,都会建立一个epitem结构体,如下所示:
struct epitem{
struct rb_node rbn;//红黑树节点
struct list_head rdllink;//双向链表节点
struct epoll_filefd ffd; //事件句柄信息
struct eventpoll *ep; //指向其所属的eventpoll对象
struct epoll_event event; //期待发生的事件类型
}
3.3 Epoll的优势是什么?
换句话说select和poll的缺点是什么?
- select单个进程能够监视的文件描述为最大为1024,轮询越多,性能越差
- Select需要复制大量句柄数据结构,开销巨大。
- Select返回整个句柄数组,程序需要遍历数组才能知道哪些句柄发生了什么事件。
- 触发方式为水平触发,如果程序没有对一个就绪的文件进行IO操作,之后每次Select调用还是会将文件描述符通知给进程。
Poll使用链表保存文件,没有1的限制,但其他三个缺点依然比较明显。
3.4 水平触发和边缘触发的区别是什么?
- 水平触发LT:默认方式,支持阻塞和非阻塞。内核告诉你某个fd就位了,如果你不对这个fd进行IO操作,内核会一直通知你。所以这种模式安全性较高。
- 边缘触发ET:只支持非阻塞,内核只会通知你一次,如果你不操作他也不管你了,速度快
3.5 谈谈什么是惊群,如何避免?
多线程在同时阻塞等待同一个事件,当事件发生时所有线程同时唤醒,然而只有一个线程能抢到控制权,其他的醒了又睡。问题主要有两方面:
- linux内核对线程频繁无效调度,影响性能
- 为了确保只有一个线程拿到资源需要加锁,影响性能
解决方案:
accept:在Linux2.6后,accept函数加入了一个标志位,只会唤醒等待队列上的第一个进程。
epoll:如果Epoll_create在fork之前创建依然有惊群现象,因为所有子进程共享epoll_create()创建的epfd,等待同一个文件描述符的所有进程/线程,都将被唤醒。在epoll: add EPOLLEXCLUSIVE flag 21 Jan 2016补丁中以accept相同的方式解决了。
4. Linux命令
1. 如何查看Linux系统有几颗物理CPU和每颗CPU的核数?
cat /proc/cpuinfo|grep -c 'physical id'
cat /proc/cpuinfo|grep 'cpu cores'|uniq
cat 命令用于连接文件并打印到标准输出设备上。 |grep是正则符号, -c表示统计数量, 正则匹配physical id。
当输入cat /proc/cpuinfo时会显示每个CPU的信息
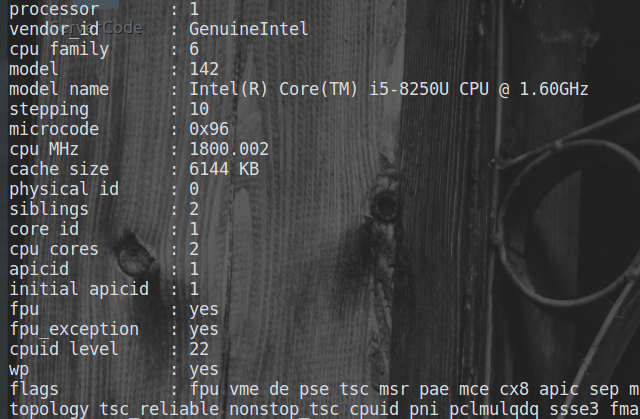
通过统计physical id出现的次数就能知道有多少颗物理CPU
2. 如何查看系统负载?
有两个命令
w
uptime
结果如下,其中load average即系统负载,三个数值分别表示一分钟、五分钟、十五分钟内系统的平均负载,即平均任务数。
➜ jr w
15:08:58 up 31 min, 1 user, load average: 0.00, 0.00, 0.00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
jr tty7 :0 14:37 31:28 12.04s 0.25s /sbin/upstart --user
3. vmstat命令各项含义
➜ jr vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 3088016 136492 976224 0 0 109 41 53 89 0 1 99 0 0
- r即running,表示正在跑的任务数
- b即blocked,表示被阻塞的任务数
- si表示有多少数据从交换分区读入内存
- so表示有多少数据从内存写入交换分区
- bi表示有多少数据从磁盘读入内存
- bo表示有多少数据从内存写入磁盘