对于关系型数据库,尤其是Mysql的面试内容的汇总,最好和Redis那一部分结合来看。
1. 数据库基本概念
1.1 三个范式
范式,即Normal Form,指的是我们在构建数据库所需要遵守的规则和指导方针。
- 首先要明确的是:满足第三范式,那么就一定满足第二范式、满足第二范式就一定满足第一范式
- 第一范式:字段是最小的的单元不可再分。即列的原子性。
- 学生信息组成学生信息表,有年龄、性别、学号等信息组成。这些字段都不可再分,所以它是满足第一范式的
- 第二范式:满足第一范式,表中的字段必须完全依赖于全部主键而非部分主键。
- 比如一个订单表中有主键(订单id,商品id)和单位价格、折扣、数量、产品名称、产品保质期。保质期只依赖于商品id,不符合第二范式。
- 第三范式:满足第二范式,非主键外的所有字段必须互不依赖
- 换句话说:数据只能存在一个表中,消除互相依赖
- 比如大学学院表中包含了学院id,院领导,院简介,如果在学生信息表中也包括了院领导,院简介这些字段,这就重复了。
1.2 什么是存储过程?
存储过程就是一段SQL语句的预编译集合,封装了一组sql语句,实现某些操作,类似于函数的功能。
好处:
- 将代码封装起来,隐藏复杂的商业逻辑
- 预编译,执行效率高
- 可以接受参数,可以回传值
坏处:
- 针对特定的某种数据库,不兼容,难维护
1.3 什么是视图
视图是从一个或多个表导出的虚拟的表,具有普通表的结构,但是不实现数据存储。
作用:
- 直观
- 安全性,暴露出视图,然后把不想让用户看到和修改的内容屏蔽掉
- 独立性,屏蔽了真实表的结构带来的影响。
缺点:
- 性能差:视图是由一个复杂的多表查询所定义
- 修改限制: 当用户试图修改视图的某些信息时,数据库必须把它转化为对基本表的某些信息的修改
1.4 超键、候选键、主键、外键是什么?
假设有如下两个表:
学生(学号,姓名,性别,身份证号,班级,教师编号)
教师(教师编号,姓名,工资)
超键:能唯一标识某条数据属性的集合。比如(学号)、(学号+姓名)、(身份证号+性别)等等。
候选键:最小的超键。比如(学号)、(身份证号)。
主键:人为规定的一个候选键,作为数据的身份象征。
外键:用于描述两个表的关系,比如学生表中包含了班主任信息(教师编号),这个就是外键。
1.5 什么是事务的隔离级别?
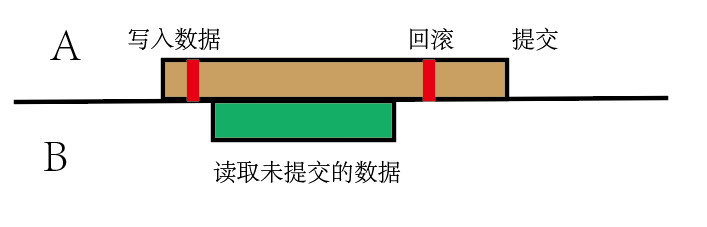
脏读:一个事务A正在访问并修改数据,他设置了数据但还没有提交,另一个事务B读到了未提交的数据。但是A可能发现出错了回滚了数据,导致B得到的数据是错的。
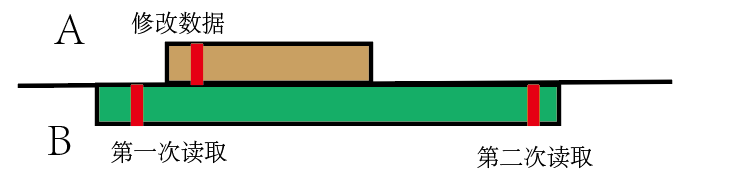
不可重复读:一个事务正在访问并修改数据,另一个事务多次读取,前后读取的数据并不相同,导致这种读取结果不可复现。
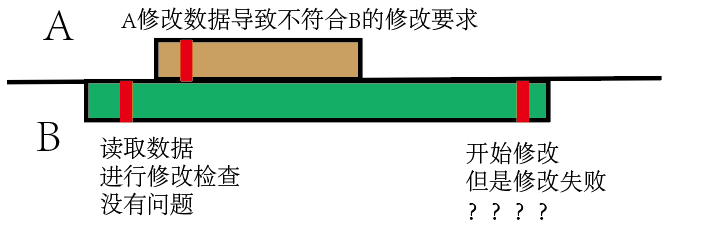
幻读:事务A正在访问并修改数据,另一个事务B也要读取修改,事务B读取时检查数据不存在符合插入条件,但在B插入之前,A插入了数据,B插入时突然发现有问题了,就像见了鬼一样。幻读侧重读-写,不可重复读侧重读-读
事务隔离级别有四个:
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | × | × |
- Read committed要求必须读取已提交的数据。
- Repeatable read要求读取过程中,其他事务不能修改(图中第一次读取第二次读取中间都算读取过程),然而读取-写入却不算在内,因此依然有幻读风险。
- Serializable要求按串行读取,效率低。
1.6 MySQL存储引擎有哪些?
最常见的是InnoDB和MyISAM
| Innodb | myisam | |
|---|---|---|
| 事务 | 支持 | 不支持 |
| 外键 | 支持 | 不支持 |
| 全文本搜索 | 不支持 | 支持 |
| 使用场景 | 频繁修改 | 查询和插入为主 |
另外还有MEMORY,存储在内存中,速度快,安全性不高。
1.7 关系型数据库和非关系型数据库的区别
关系型数据库
- 优点:易于理解,支持SQL可用于复杂查询
- 缺点:读写性能差,高并发能力差
非关系型数据库NoSQL
- 优点:键值对存储,读写性能高;键值对读写,数据没有耦合性,易拓展
- 缺点:缺乏sql支持,不适用于复杂查询
2. SQL语句
2.1 drop、truncate、delete区别
- 不再需要一张表的时候,用drop
- 想删除部分数据行时候,用delete,并且带上where子句
- 保留表而删除所有数据的时候用truncate
2.2 varchar 和 char区别
前者可变长度,后者固定长度
2.3 各种join
left join 左关联,主表在左边,右边为从表。如果左侧的主表中没有关联字段,会用null 填满。right join相反
inner join 内关联只会显示主表和从表相关联的字段,不会出现null
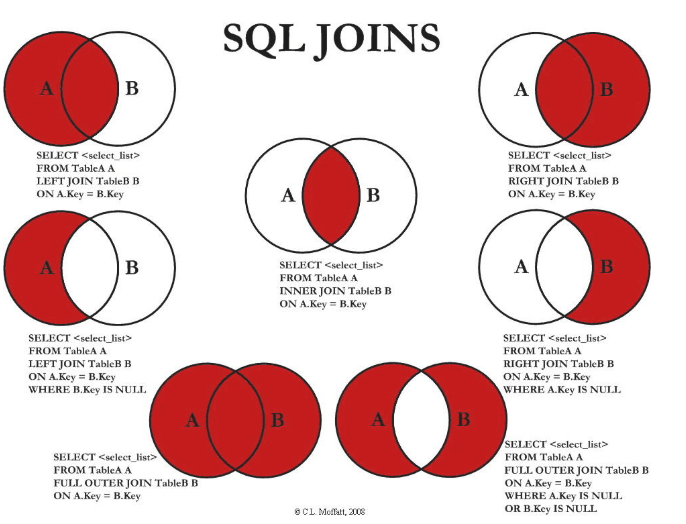
cross join则是将两个表的字段两两组合,比如A表有4个,B表有3个,则crossjoin出来就有12个
2.4 SQL约束有哪些
- NOT NULL: 用于控制字段的内容一定不能为空(NULL)。
- UNIQUE: 控件字段内容不能重复,一个表允许有多个 Unique 约束。
- PRIMARY KEY: 也是用于控件字段内容不能重复,但它在一个表只允许出现一个。
- FOREIGN KEY: 设置外键约束,假设表1是主表,表2是附表,学号作为外键。那么,如果表2要插入一条数据,表1必须有个学号;同理,如果表1要删除1条数据,表2必须先删除。
- CHECK: 用于控制字段的值范围。
3. 索引
3.1 什么是索引,什么时候使用索引?
索引本身就是一种数据结构,用于加快查找速度,InnoDB和MyISAM都是用的B+树。
- 经常需要查询,经常使用SELECT和WHERE操作时,可以使用索引
- 经常做表连接
- 经常出现在order by、group by、distinct 后面的字段中,可以建立索引
索引的缺点在于:增删改浪费时间,构建索引需要占据空间
3.2 构建索引常用的数据结构有哪些
| 结构 | 区别 |
|---|---|
| Hash | 只存储对应的哈希值,查找速度快,不能排序,不能进行范围查询 |
| B+ | 数据有序,范围查询 |
3.3 聚集索引和非聚集索引区别?
| 索引 | 区别 |
|---|---|
| 聚集索引 | 数据按索引顺序存储,数据行的物理顺序与列值的顺序相同 |
| 非聚集索引 | 存储指向真正数据行的指针 |
聚集索引如下
| 地址 | id | username | score |
|---|---|---|---|
| 0x01 | 1 | 小明 | 90 |
| 0x02 | 2 | 小红 | 80 |
| 0x03 | 3 | 小华 | 92 |
非聚集索引就不是按照地址存储,每一个都有一个指针,指向不同地方。
3.4 为什么底层用B+树而不是红黑树?
| 树 | 区别 |
|---|---|
| 红黑树 | 增加,删除,红黑树会进行频繁的调整,来保证红黑树的性质,浪费时间 |
| B树也就是B-树 | B树,查询性能不稳定,查询结果高度不致,每个结点保存指向真实数据的指针,相比B+树每一层每屋存储的元素更多,显得更高一点。 |
| B+树 | B+树相比较于另外两种树,显得更矮更宽,查询层次更浅 |
3.5 索引失效的条件有哪些?
在where子句中进行null值判断
SELECT id FROM table WHERE num is null 在建立数据库的时候因尽量为字段设置默认值,如int类型可以使用0,varchar类型使用 ''避免在where子句中使用
or来连接条件,因为如果俩个字段中有一个没有索引的话,引擎会放弃索引而产生全表扫描避免在where子句中使用
like模糊查询
4. 提高性能的方法
4.1 SQL语句优化的步骤是什么?
(1)发现有问题的SQL
读取MYSQL的慢查询日志,记录在MySQL中响应时间超过阈值的语句,可以查询出执行的次数多占用的时间长的SQL。
(2)通过EXPLAIN关键字分析SQL
使用 EXPLAIN 关键字可以知道MySQL是如何处理你的SQL语句的
(3)进行优化
4.2 优化SQL语句的方法有哪些?
(1)选择最有效率的表名顺序
数据库的解析器规则:FROM子句中写在最后的表将被最先处理,因此:
- 如果是多个表连接查询,将引用最多的表放在最后,优先处理可以加快后续的速度。
(2)where的连接顺序
自右而左的顺序解析WHERE子句
- 可以过滤掉最大数量记录的条件写在WHERE右边
(3)多使用内部函数提高SQL效率
比如,使用mysql的concat()函数会比使用||来进行拼接快,因为concat()函数已经被mysql优化过了。
(4)建立索引
建立条件,参看3.1
4.3 数据库连接池的作用
维护一定数量的连接,减少重新创建连接的时间
4.4 什么是MVCC
MVCC,Multi-Version Concurrency Control,多版本并发控制。
使用MVCC时,不会直接用新数据覆盖旧数据,而是将旧数据标记为过时并在别处增加新版本的数据。允许读者读取在他读之前已经存在的数据,即使这些在读的过程中半路被别人修改、删除了,也对先前正在读的用户没有影响。