本篇针对的是问答题而不是编程题,所以大部分都是在文字叙述,外加少部分的编程。
1. 树
1.1 区分完全二叉树、满二叉树、搜索二叉树
完全二叉树:假设树有N层,则第1到第N-1层都是满节点
满二叉树:满足完全二叉树,但第N层没有任何节点
二叉搜索树:任意节点的左子树不为空,则左子树的所有值均小于根节点;反之右子树大于根节点。
1.2 什么是平衡二叉树(VAL树)?
满足三个条件:
- 是二叉搜索树
- 左右子树深度之差不大于1
- 左右子树分别都是平衡二叉树
1.3 什么是哈夫曼树?
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,则称其为最优二叉树,也叫哈夫曼树。特征是权值较大的结点离根较近。
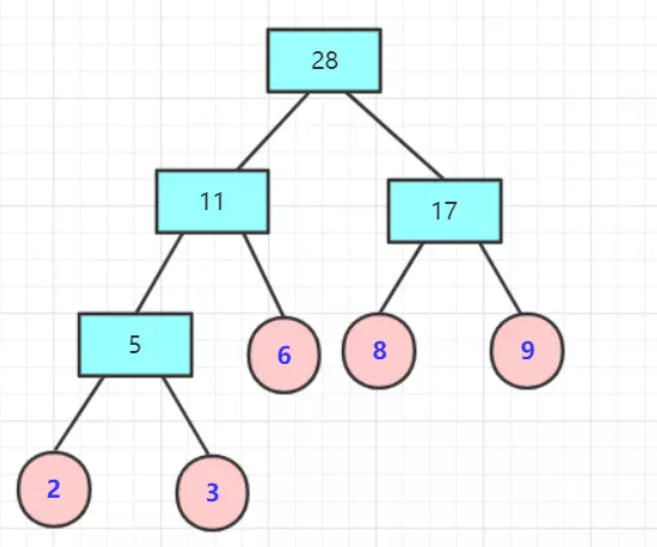
构建时,先对叶节点的权值排序,然后合并:
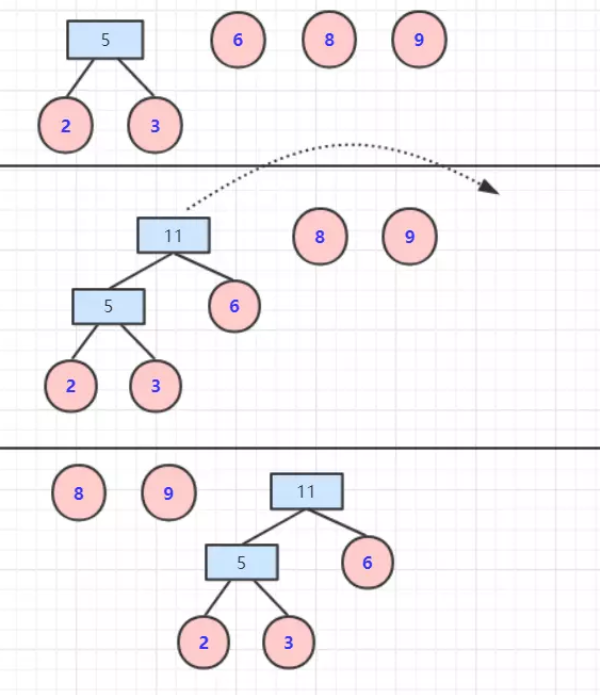
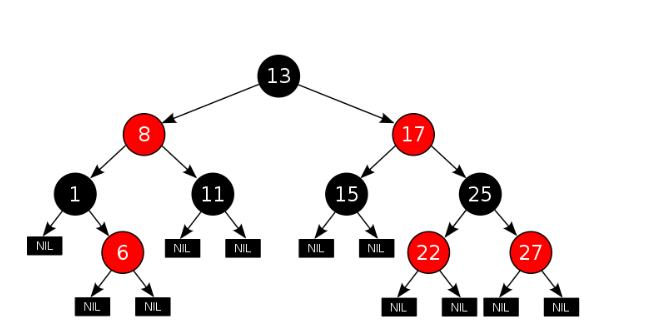
1.4 什么是红黑树?
特性:自平衡
时间复杂度:普通二叉搜索树的时间复杂度为$O(\lg n)$到$O(n)$,而红黑树能保持在lgn。最极端的情况:最长子树是最短子树的两倍。
五大原则:
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]**
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
维持自平衡的方法:左旋,右旋,变色
1.5 什么是红黑树的左旋右旋?


代码实现:
- 节点左旋必须有右孩子,右旋必须有左孩子。
- 如果N经过旋转变成了根节点,一定要记得将RBTree结构体中的根节点指针root指向N,这是容易出错的地方。
const (
// 左旋
LEFTROTATE bool = true
// 右旋
RIGHTROTATE bool = false
)
// rotate() true左旋/false右旋
// 若有根节点变动则返回根节点
func (rbnode *RBNode) rotate(isRotateLeft bool) (*RBNode, error) {
var root *RBNode
if rbnode == nil {
return root, nil
}
if !isRotateLeft && rbnode.left == nil {
return root, errors.New("右旋左节点不能为空")
} else if isRotateLeft && rbnode.right == nil {
return root, errors.New("左旋右节点不能为空")
}
parent := rbnode.parent
var isleft bool
if parent != nil {
isleft = parent.left == rbnode
}
if isRotateLeft {
grandson := rbnode.right.left
rbnode.right.left = rbnode
rbnode.parent = rbnode.right
rbnode.right = grandson
} else {
grandson := rbnode.left.right
rbnode.left.right = rbnode
rbnode.parent = rbnode.left
rbnode.left = grandson
}
// 判断是否换了根节点
if parent == nil {
rbnode.parent.parent = nil
root = rbnode.parent
} else {
if isleft {
parent.left = rbnode.parent
} else {
parent.right = rbnode.parent
}
rbnode.parent.parent = parent
}
return root, nil
}
1.6 红黑树相较于AVL树的优势是什么?
AVL树是绝对平衡的二叉树,所有子树都必须满足深度之差为1的强条件,这会对插入删除带来较大的麻烦。而红黑树可以能确保树的最长路径不大于两倍的最短路径的长度(依然可以保证lgn),虽然查找时性能没有AVL树那么好,但增添和删除更为便捷。
1.7 红黑树和哈希表二者该如何选择?
考虑三个方面:
- 内存:如果内存有限制,使用map能节约内存
- 数据量:如果数据量较小,使用map比较好。反之,数据量大,map的层数太多,用哈希表比较好。
- 扩展性:如果数据是静态的,哈希表会比较好。如果需要拓展,则红黑树比较好。
1.8 红黑树在什么情况下可能发生红黑节点冲突?
插入操作时,需要解决红红冲突,因为红黑树的一条性质是如果一个节点是红色的,那么其子节点都是黑色的。
1.9 map和unordered_map的底层实现有什么不同?
map底层是基于红黑树实现的,因此map内部元素排列是有序的。而unordered_map底层则是基于哈希表实现的,因此其元素的排列顺序是杂乱无序的。
1.10 什么是B-树
-是连接符,不读B减,是一种多路搜索树。所有的非终端结点中包含下列信息数据:(n,A0,K1,A1,K2,A2,…,Kn,An);
n 表示结点中包含的关键字的个数,取值范围是:⌈m/2⌉-1≤ n ≤m-1。Ki (i 从 1 到 n)为关键字,且 Ki < Ki+1 ;Ai 代表指向子树根结点的指针,且指针 Ai-1 所指的子树中所有结点的关键字都小于 Ki,An 所指子树中所有的结点的关键字都大于 Kn。
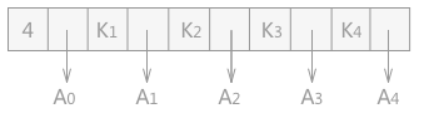
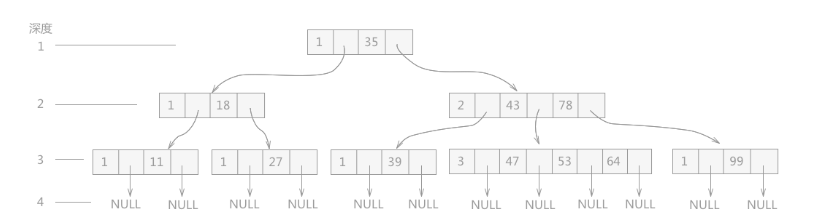
所示就是一棵 4 阶的 B-树,这棵树的深度为 4:
1.11 什么是B+树
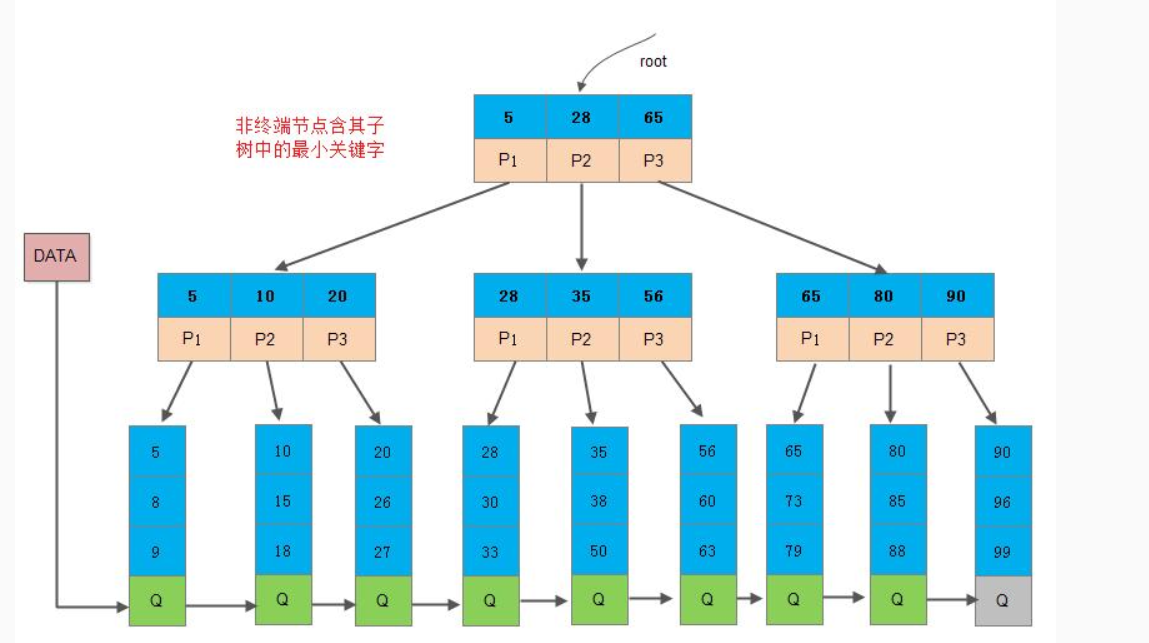
- B+树所有叶子节点的链表中包含了全部关键字的信息, 及指向含这些关键字记录的指针
- 叶子节点的链表是有序的
- 非终端节点只是索引的一部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字
2. 堆栈
2.1 什么时候可能发生栈溢出
- 局部数组过大。解决办法:增大栈空间或者使用动态分配(堆空间)
- 递归调用层次太多。递归函数在运行时会执行压栈操作,当压栈次数太多时,也会导致堆栈溢出。
- 指针或者数组越界。
2.2 堆和栈的区别
- 地址方向:堆是由低地址向高地址扩展;栈是由高地址向低地址扩展
- 管理方式:堆中的内存需要手动申请和手动释放;栈中内存是由OS自动申请和自动释放
- 使用效率:堆中频繁调用malloc和free,会产生内存碎片,降低程序效率;而栈由系统分配,不会产生内存碎片
2.3 什么是小根堆和大根堆?
小根堆:
- 若存在左子节点,则根节点的值小于左子节点
- 若存在右子几点,则根节点的值小于左子节点
大根堆,小于换成大于。
3. 排序
3.1 选择排序
选择一组数列中最小的一个放到前面去。
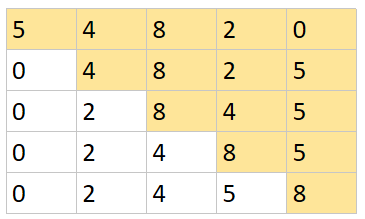
func selectSort(b []int) []int {
n:=len(b)
a:=make([]int,n)
copy(a,b)
for i:=0;i<n;i++{
min:=i
for j:=min+1;j<n;j++{
if a[j]<a[min]{
min=j
}
}
swap(a,i,min)
}
return a
}
选择、插入、希尔都是N^2级别的排序,希尔的平均速度要快于前两种。
3.2 插入排序
对于某数n来说,前n-1个数已经完成排序,则n要插入到其中正确的位置。编程时双循环,第一个循环表明确定序列的范围,第二个循环则是将n与n-1,n-2…相比较,确定位置(冒泡)
func insertSort(b []int)[]int{
n:=len(b) //切片传进来都是地址,要拷贝
a:=make([]int,n)
copy(a,b)
for i:=1;i<n;i++{
for j:=i;j>=1;j--{
if a[j-1]>a[j]{ //注意这里的符号
swap(a,j-1,j)
}
}
}
return a
}
void inserSort(vector<int>& a) {
int n = a.size();
for (int i = 1; i < n; i++) {
for (int j = i; j >= 1; j--) {
if (a[j - 1] > a[j]) {
swap(a[j - 1], a[j]);
}
}
}
}
3.3 希尔排序
也就是分组插入排序,编程时三重循环,第一重是步长选择,初始值为length/2,每次迭代都除以2,直到为0;后面两重循环和插入排序一模一样,只不过把i替换为step;比如正常插入排序i=1,把1替换为step即可完成希尔排序。
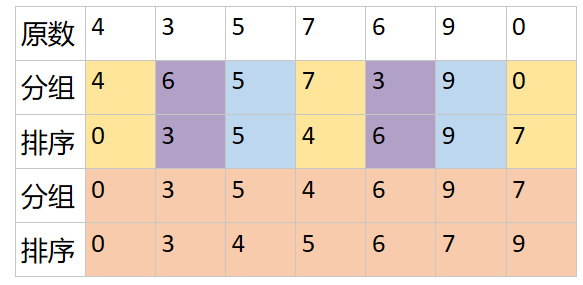
func shellSort(b []int)[]int{
n:=len(b)
a:=make([]int,n)
copy(a,b)
for step:=n/2;step>=1;step=step/2{ //分组
for i:=step;i<n;i++{ //在不同组内进行
for j:=i;j>=step;j=j-step{
if a[j-step]>a[j] {
swap(a, j-step, j)
}
}
}
}
return a
}
void shellSort(vector<int>& a) {
int n = a.size();
for (int len = n / 2; len >= 1; len = len / 2) {
for (int i = len; i < n; i++) {
for (int j = i; j >= len; j--) {
if (a[j - len] > a[j]) {
swap(a[j - len], a[j]);
}
}
}
}
}
3.4 归并排序
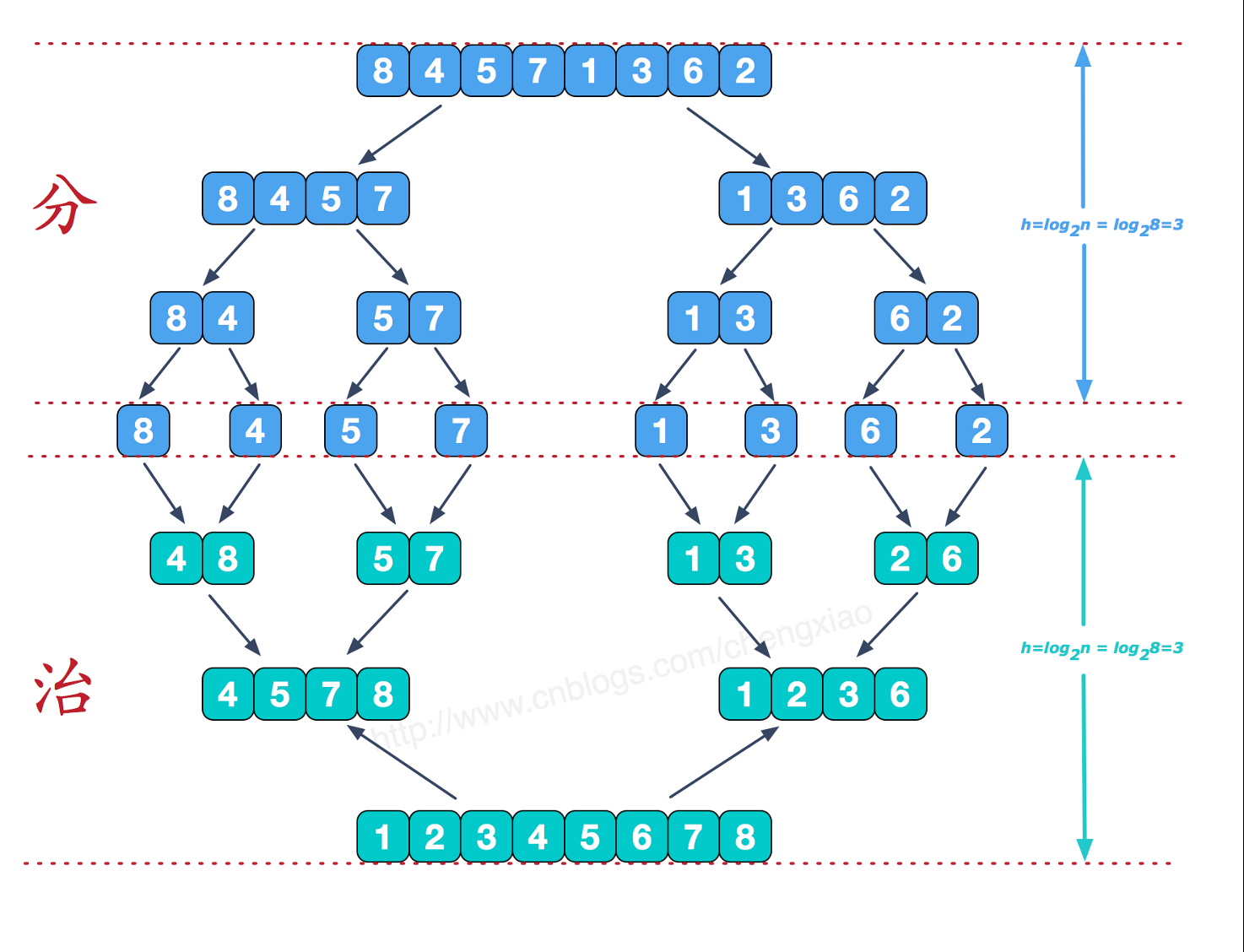
func mergeSort(b []int) []int{
n:=len(b)
a:=make([]int,n)
copy(a,b)
//在排序前,先建好临时数组,避免递归中频繁开辟空间
tmp:=make([]int,n)
sort(a,0,n-1,tmp)
return a
}
func sort(a []int,left int, right int, tmp []int){
if left<right{
mid:=(left+right)/2
sort(a ,left,mid,tmp) //左半边归并
sort(a, mid+1,right,tmp) //右半边归并
merge(a,left,mid,right,tmp)
}
}
func merge(a []int,left,mid,right int,tmp []int){
i,j,t:=left,mid+1,0
for i<=mid&&j<=right { //融合的前提是左半边和右半边分别有序
if a[i]<=a[j]{
tmp[t]=a[i];t++;i++
}else{
tmp[t]=a[j];t++;j++
}
}
//一边比完后,就把剩下的一边全放进去
for i<=mid{
tmp[t]=a[i];t++;i++
}
for j<=right{
tmp[t]=a[j];t++;j++
}
t=0
for left<=right{//将排好的放回原数组
a[left]=tmp[t];left++;t++ //必须有left!!!!
}
}
大O代表的算法法复杂度一样只是说明随着数据量的增加,算法时间代价增长的趋势相同。在公式里各个排序算法的前面都省略了一个c,这个c对于堆排序来说是100,可能对于快速排序来说就是10,但因为是常数级所以不影响大O。
https://blog.csdn.net/qq_39521554/article/details/79364718
void merge(vector<int>& a, int left, int right, int mid) {
vector<int> tmp(right - left+1,0);
int p1 = left, p2 = mid + 1, index = 0;
while (p1 <= mid && p2 <= right) {
tmp[index++] = a[p1] > a[p2] ? a[p2++] : a[p1++];
}
while (p1 <= mid) {
tmp[index++] = a[p1++];
}
while (p2 <= right) {
tmp[index++] = a[p2++];
}
for (int i = 0; i < tmp.size(); i++) {
a[left + i] = tmp[i];
}
}
void cut(vector<int>& a, int left, int right) {
if (left < right) {
int mid = (left + right) / 2;
cut(a, left, mid);
cut(a, mid + 1, right);
merge(a, left, right, mid);
}
}
void mergeSort(vector<int>& a) {
if (a.size() < 2) return;
cut(a, 0, a.size() - 1);
}
3.5 快速排序
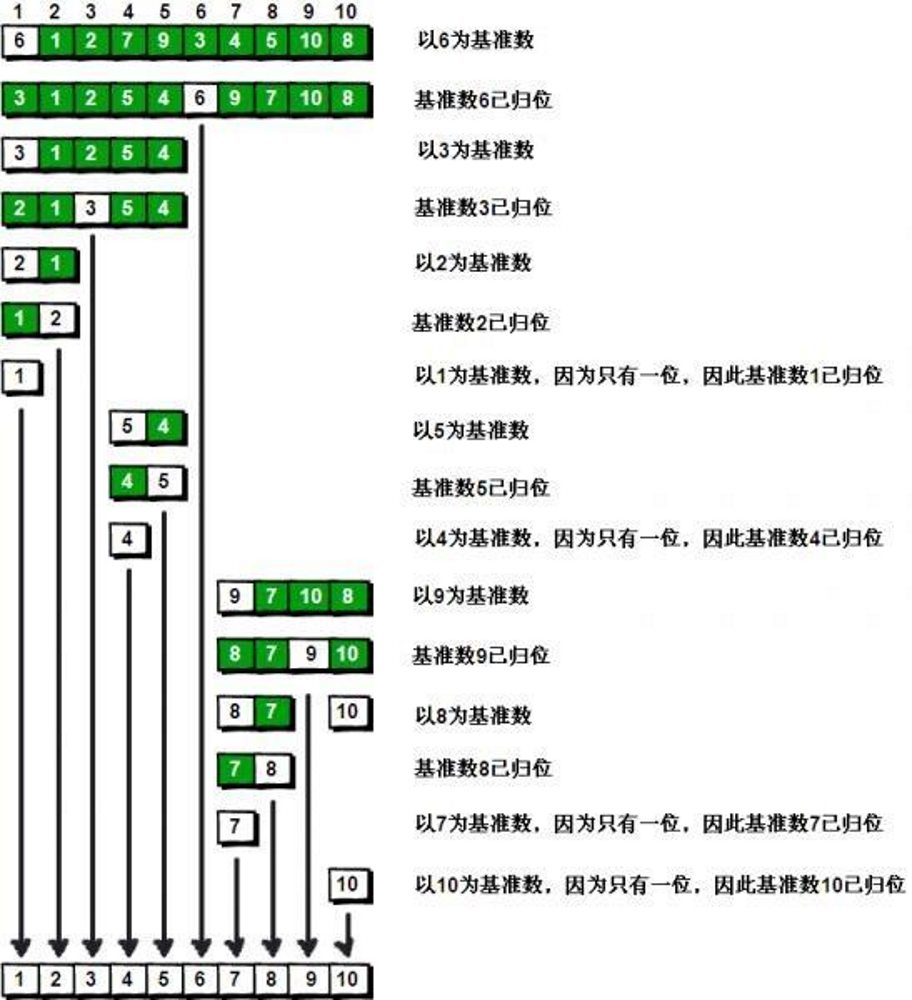
func quickSort(a []int,left,right int){
if left<right{
i,j:=left,right
mid:=(left+right)/2
key:=a[(left+right)/2] //取中间作为pivot,效率更高
for i<=j{ //调序,直到满足条件
for a[i]<key{ //到key时一定会停
i++
}
for a[j]>key{
j--
}
if i<=j { //交换之前必须检查
a[i], a[j] = a[j], a[i]
i++;j--
}
}
if left<mid-1{ //满足条件时,i一定大于j
quickSort(a,left,mid-1)
}
if right>mid+1{
quickSort(a,mid+1,right)
}
}
}
void quickSort(vector<int>& a, int left, int right) {
if (left < right) {
int i = left, j = right;
int mid = (left + right) / 2;
int pivot = a[mid];
while (i <= j) {
while (a[i] < pivot) {
i++;
}
while (a[j] > pivot) {
j--;
}
if (i <= j) {
swap(a[i], a[j]);
i++, j--;
}
}
if (left < mid - 1) {
quickSort(a, left, mid - 1);
}
if (right > mid + 1) {
quickSort(a, mid + 1, right);
}
}
}
3.6 三项切分快速排序
采用了三指针,两个放首尾,index放中间。要保证index以前的都是有序的,我们构建两个标志zerotail和twohead分别表示最后一个0的下一个和第一个2的前一个,比如[0,1,1,2],zerotail=1,twohead=2。
注意:当nums[index] == 2交换时,index不能盲目前进,因为不知道被换过来的是1还是2,需要放到下一轮进行检验。(由于我们保证了index以前都是有序的,所以和0做交换是安全的)
注意:去重时,必须要判断twohead >= 0和zerotail < nums.size(),不然会溢出。比如[2],使得twohead=-1,下一次while就会导致nums[twohead]溢出。
void sortColors(vector<int>& nums) {
int zerotail = 0, twohead = nums.size() - 1;
while (zerotail < nums.size() && nums[zerotail] == 0) zerotail++;
while (twohead >= 0 && nums[twohead] == 2) twohead--;
int index = zerotail;
while (index <= twohead)
{
if (nums[index] == 0)
std::swap(nums[zerotail++], nums[index++]);
else if (nums[index] == 2)
std::swap(nums[twohead--], nums[index]);
else
index++;
}
}
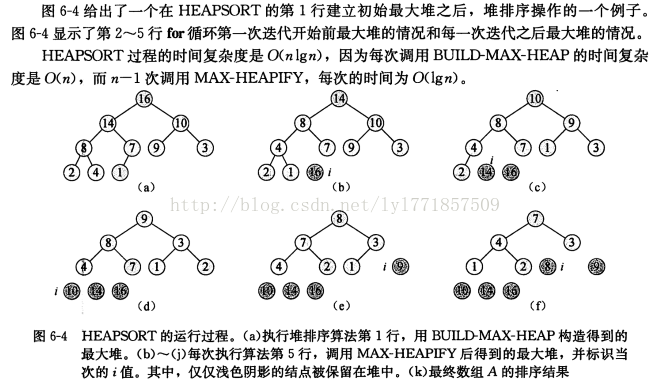
3.7 堆排序
当堆中某个节点的编号为i时,如果这个节点有左右子树,那么左子树的节点编号为2*i,右子树的节点编号为2*i+1
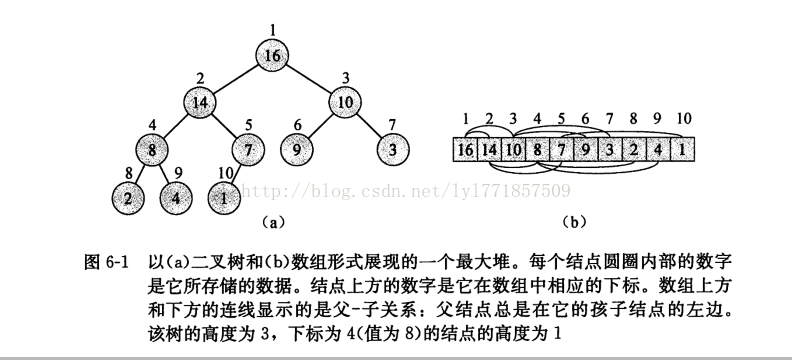
先用buildMaxHeap将数组构建成最大堆(第i层总是比第i+1层大)。因为数组中最大元素总在根节点A[0]处,每次都取出最大值,然后放入res数组。同时维护被破坏的堆。
int nsize;//因为每次移除根节点,size都会变小,所以需要全局变量掌控
void maxHeap(vector<int>& a, int n) {
int leftChild, rightChild, largest;
leftChild = 2 * n;
rightChild = 2 * n + 1;
if (leftChild <= nsize && a[leftChild - 1] > a[n - 1]) {
largest = leftChild;
}
else {
largest = n;
}
if (rightChild <= nsize && a[rightChild - 1] > a[largest - 1]) {
largest = rightChild;
}
if (largest != n) {
swap(a[n - 1], a[largest - 1]);
maxHeap(a, largest);
}
}
void buildHeap(vector<int>& a, int n) {
int i = n / 2;
for (; i > 0; i--) {
maxHeap(a, i);
}
}
void heapSort(vector<int>& a, int n) {
nsize = n;
int i;
buildHeap(a, n);
vector<int> res;
for (i = nsize; i > 0; i--)
{
res.push_back(a[0]);
a.erase(a.begin());
nsize=nsize-1;
maxHeap(a, 1);
for (auto x : res) {
cout << x << ",";
}
cout << endl;
}
}
3.8 TopK问题
(1)分治法
/*
* 基于快排Partition函数
* 时间复杂度O(n)空间复杂度O(1)需要改变输入
*/
vector<int> getTopK(vector<int> nums, int k){
if (nums.empty() || k > nums.size() || k<=0) return {};
vector<int> ret;
int begin = 0, end = nums.size()-1;
int idx = Partition(nums,begin,end);
while (idx != k-1){
if (idx < k-1){
begin = idx + 1;
idx = Partition(nums,begin,end);
}else{
end = idx - 1;
idx = Partition(nums,begin,end);
}
}
for (int i = 0; i < k; ++i) {
ret.push_back(nums[i]);
}
return ret;
}
// 返回索引值idx,idx前的元素均大于该处的元素值;idx后的元素均小于该处的元素值
int Partition(vector<int> &nums, int begin, int end){
if (begin > end) return begin;
int key = nums[begin]; // 取最后一个值为基准值
while (begin < end){
while (nums[end] <= key && begin < end) --end;
nums[begin] = nums[end];
while (nums[begin] > key && begin < end) ++ begin;
nums[end] = nums[begin];
}
nums[begin] = key;
return begin;
}
(2)堆排序
时间复杂度nlg(K),比分治法n要慢,但是不需要修改输入数据,适用于海量数据。
multiset<T> 容器就像 set<T> 容器,但它可以保存重复的元素,默认用 less<T> 来比较元素,也可以greater<T>
vector<int> getTopK(vector<int>& nums, int k){
if (nums.empty() || k > nums.size() || k<1) return {};
vector<int> ret;
multiset<int, less<int>> m; // 最小堆,保存最大的K个数
for (int i = 0; i < nums.size(); ++i) {
if(m.size()<k){
m.insert(nums[i]);
} else{
it = m.begin();
// 如果当前值大于topK的最小元素(最小堆堆顶),替换该值
if (nums[i]> *it){
m.erase(it);
m.insert(nums[i]);
}
}
}
for (auto x : m) {
ret.push_back(x);
}
return ret;
}
4. 哈希
4.1 什么是哈希表?
又称散列表。通过键-值映射进行访问的表,把键映射到数组的某个下标来加快查找速度。
4.2 哈希表的定址方法有哪些?
- 直接法:key=value+C,C是常量
- 取余法:key=value%C
- 折叠法:比如value=135790,将value变为13+57+90=160,再去除最高位,得到的60就是key。
4.3 哈希表解决冲突的办法有哪些?
线性探测:5421 是要插入数据的位置,若被占用就使用5422,以此类推
二次探测:防止聚集,线性探测是x+1,x+2,而二次探测就是x+1,x+4,x+9
再哈希法:消除原始聚集和二次聚集,把关键字用不同的哈希函数再做一遍哈希化,用这个结果作为步长
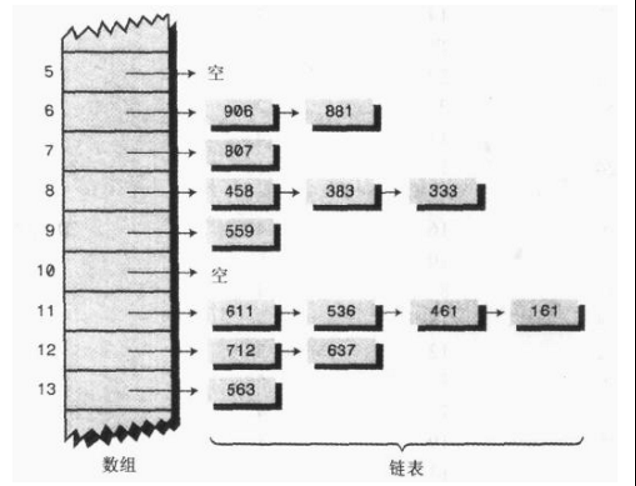
链地址法:某个数据项的关键字值还是像通常一样映射到哈希表的单元,而数据项本身插入到这个单元的链表中。其中每一条链子都是一个桶。假设桶的个数为17,则将哈希值取17的模即可分配。
4.4 为什么哈希表的桶的个数是质数
取合数会导致某些位失效,比如如果桶的个数是2^3=8,那么第4位就会失效:
H( 11100 ) = H( 28 ) = 4
H( 10100 ) = H( 20 )= 4