1. 基本概念
1.1 string和char数组的区别
string的字面值是char数组,可以将string理解为vector<char>。
字符串字面值不能相加:
string s5 = "hello" + ", "; // 错误,两个运算对象都不是 string
string s1=s2+"1"; //ok
1.2 unsigned类型
unsigned类型是unsigned int的简写。范围0-255,超出结果会wrap around环绕。
int x=1e10; //得到一个随机值
unsigned s=257 //得到1
要小心:
for (unsigned u = 10; u >= 0; --u)
std::cout << u << std::endl //死循环
1.3 变量初始化方法
初始化的办法有4种:
int a=0;
int a={0};
int a(0);
int a{0};
花括号初始化成为list initialization,编译器能帮助我们阻止信息丢失。
long double pi=3.1415926535;
int a{pi}; //error
int a=pi; //ok,but loss information
1.4 引用和指针
引用是另一个变量的别名。只能绑定某个对象,不能绑定字面值或者表达式的结果,int &a=10;就是错的。
指针是一个复合类型:改造符*+基本类型。我们可以使用解引用(derefence)运算符来访问对象。注意:**定义的时候 是一个modifier,使用的时候是一个 dereference,概念不一样!**
空指针的意思是:没有任何一个对象和指针绑定。void*是一个特殊的指针类型,可以承载任意类型的对象的地址,但类型时未知的。
double dval =3.14;
void* pv = &dval;//pv还是 void*类型
二者区别:
相同点:
- 都是复合类型(基本类型+改造符或声明符)
- 都是间接访问
不同点:
- 指针本身就是一个对象而引用不是,所以指针可以被赋值和拷贝,而引用不能。指针不需要定义时初始化。
- 一个指针可以指向好几个不同的对象,而引用则被绑死
1.5 类和结构体的区别
class
- class 在堆中分配空间,栈中保存的只是引用
- 默认是private
struct
- struct 在栈中分配空间
- 默认是public
1.6 IO特性
我们希望IO以流的形式输入输出数据,所以不希望被干扰,因此IO类没有拷贝和赋值函数。
1.8 IO刷新缓冲区的原因
- 程序跑完,从main中返回
- 缓冲区满
- 特殊符号endl,flush,ends结尾
- 使用unitbuf操作符,默认情况下,unitbuf为cerr默认设置
前面提到了用endl,flush,ends结尾。我们最常用的endl:结束当前行,刷新缓冲区。flush刷新缓冲区,末尾不添加字符,而ends除了刷新缓冲区外,末尾还会添加一个空字符。
注意:程序崩了是不刷新缓冲区的。
1.9 全局变量和局部变量有什么区别?编译器是怎么判断的?
全局变量的生命周期伴随主程序(不是主函数)的创建和销毁,局部变量只存在于局部函数内部。
全局变量分配在全局数据段,而局部变量则分配在堆栈里面。
1.10 生成可执行文件的过程
- 用编辑器编写源代码,如.c文件。
- 用编译器编译代码生成目标文件,如.o。
- 用链接器连接目标代码生成可执行文件,如.exe。
1.11 cmake和makefile区别
利用make工具可以根据makefile批量处理源文件。而cmake可以读取所有源文件后,自动生成makefile,更加方便。
1.12 int (*s[10])(int) 表示的是什么?
int (*s[10])(int) 函数指针数组,每个指针指向一个int func(int param)的函数。
int (*fp)(int a);
//fp可以指向如下函数
int myFunction(int a){...}
1.13 联合
一个 union 可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值。当某个成员被赋值后其他成员变为未定义状态。
union abc {
int i;
char m;
};
union abc a;
a.i = 10;
2. 关键词和操作符
2.1 extern
CPP初始化通常分为两个部分:
- 声明,让程序知道他的名字
- 定义,实现实体。
用extern关键词来进行声明,这样就不用进行显示初始化。
对比:
extern int a;
int b;
2.2 constexpr
当一个变量声明为const时,我们并不知道它是编译期可知还是运行期可知。
const int a=10; //constant expression
const int b=get_size(); //non a constant expression
关键词constexpr就是指编译期可知,潜台词是:告诉编译器我可以是编译期间可知的,尽情的优化我吧。而const专门用来声明不变量,潜台词是:告诉程序员没人动得了我,放心的把我传出去;或者放心的把变量交给我,我啥也不动就瞅瞅。
另一个作用是让类的静态成员在类间能够初始化:
class Account
{
public:
static double rate() { return interestRate; }
static void rate(double);
private:
static constexpr int period = 30;// period is a constant
}
2.3 sizeof
它不是一个关键词,而是一个运算符!!!以位的形式返回表达式结果的大小。
vector<int> a{1,2,3};
auto m = sizeof a; // type is unsigned_int64, m = 32
auto n = sizeof a[0]; //type is the same as above, n=4;
2.4 mutable
在成员函数参数列表后加上关键字const后,该函数不允许修改类的数据成员。
char Screen::get() const {
return _screen[_cursor];
}
对成员变量加上mutable关键词可以消除const的影响:
class Screen {
public:
void some_member() const;
private:
mutable size_t access_ctr;
}
void Screen::some_member() const {
++access_ctr;
}
2.5 explicit
使用关键词explicit抑制隐式转化:
class A{
public:
explicit A(int size){}
explicit A(const Explicit& ins){}
};
int main(){
A test0(15);
A test1 = 10;// 无法调用
A test5 = test0;//无法调用
//如果去掉explicit,就都可以调用。
}
2.6 inline
声明为内联函数,则:
- 相当于把内联函数里面的内容写在调用内联函数处;
- 相当于不用执行进入函数的步骤,直接执行函数体;
优点:省去了代码展开,提高速度;缺点:代码体积膨胀。
2.7 volatile
作用:阻止编译器优化,确保编译器总是从内存中读取数据
原因:因为访问寄存器要比访问内存单元快的多,所以编译器一般优化代码,尽量读取寄存器,但在多线程过程中可能会读脏数据。
2.8 typedef struct
struct Student{
int a;
}stu1;//stu1是一个变量
typedef struct Student2{
int a;
}stu2;//stu2是一个结构体类型
auto m = stu1.a; //ok
auto n = stu2.a; //error
stu2 st;
auto n = st.a;//ok
3. new
3.1 new和delete的执行过程
new的步骤:
- 分配一块足够大的原始的未命名的内存空间
- 调用相应的构造函数构造对象,为其传入初值
- 构造结束后返回该对象的指针
delete步骤:
- 调用对象的析构函数
- 编译器释放内存空间
3.2 动态数组
有的时候编译时并不能确定数组长度,我们需要通过动态方式分配长度。
int* p = new int[obj.getlen()]; // new运算符返回第一个元素的地址。
delete [] p; // 释放整个数组,new如果带[] 则delete也需要带[]
使用new和delete时,应遵守以下规则
- 避免使用delete来释放不是new分配的资源;
- 不要对同一资源delete两次
- 使用new[]分配资源时,应使用delete[]来释放
- 可以对空指针delete
3.3 智能指针
使用new关键词分配动态内存会返回指向对象的指针。为了避免管理内存的麻烦,引入带有OS机制的智能指针:
- shared_ptr,允许多个指针指向同一个对象
- unique_ptr,对对象拥有唯一所有权,可以移动但不能复制
- weak_ptr,和shared_ptr搭配使用检测他是否空悬,每次使用时不会影响指向对象的引用计数
这几个指针的使用规则:
使用shared_ptr:
初始化时,最好用函数分配内存,也可以传统的new分配
shared_ptr<string> p1=make_shared<string>("hello");
shared_ptr<int> p2=make_shared<int>();//empty
shared_ptr<int> p3(new int(10));
reset函数作用
p = std::make_shared<int>(5);
p.reset(new int(5));//等价
p = nullptr;
p.reset();//等价
使用unique_ptr:
不像shared_ptr那样有函数可以用,unique_ptr必须要用new分配空间:
unique_ptr<int> p2(new int(42));
它不能被拷贝和赋值:
unique_ptr<int> p1=new int(42);
auto p2(p1);//error
auto p3 = p1;//error
但我们可以用reset和release转移
unique_ptr<int> p1(new int(42));
unique_ptr<int> p2(p1.release());
unique_ptr<int> p3(new int(10));
p3.reset(p2.release);
使用release的时候要特别小心,auto会默认推导为普通指针类型,所以需要手动delete,不然就泄露了。
auto p2(p1.release()); //int*
在函数中,我们能够将unique_ptr传递出去:
unique_ptr<int> help(A a){
unique_ptr<A> pa(new A(a));
return pa;
}
3.4 new和malloc区别
总结起来就是两反,两内,两重(反冲累),狗租户(返回类型,失败返回,内存位置,内存大小指定,重新分配内存,重载,构造,数组,互相调用)
1.返回类型
new操作符分配成功是返回的指针类型和预期结果相同,无序进行转化,而malloc返回为void*,需要强制转化
char* p1=static_cast<char>(malloc(10));
2.失败返回
new分配失败时,抛出bad_alloc异常,而malloc失败时返回NULL。
3.内存位置
new从自由内存区申请(free store),malloc从堆上申请。自由内存区可以是堆也可以不是,这取决于实现细节,也可以是静态内存区。
4.是否指定内存大小
new分配时无须指定内存块的大小,编译器自行计算,而malloc则需要显式指出内存大小。
5. 是否可以被重载
new和delete可以,malloc不可以
6. 重新分配内存
使用malloc分配的内存后,可以使用realloc函数进行内存重新分配实现内存的扩充。如果原地内存足够则直接扩大,如果不足则重新找一块地方。new不具备重新分配的能力,只能另起炉灶。
7. 构造函数
new会调用构造函数和析构函数,而malloc只是分配内存空间。
8. 处理数组
C++提供了new[]和delete[]来专门处理数组。注意delete[]要与new[]配套使用,不然会找出数组对象部分释放的现象,造成内存泄漏。
A * ptr = new A[10];//分配10个A对象
delete [] ptr;
malloc需要手动指定数组大小:
int * ptr = (int *) malloc( sizeof(int)* 10 );//分配一个10个int元素的数组
9. 是否可以互相调用
new可以重载调用malloc,而malloc反过来则不行。
4. const
4.1 const和#define相比优点是什么?
define是宏定义,只是换了一个名字。而使用const时编译器会对const进行类型检查。
4.2 const用处
(1)变量被指定为const
一个变量被指定为const类型后,不能再赋值:
const int bufsize =512;
bufsize =100; //error
(2)引用被指定为const
对于const变量的引用也不能再赋值:
const int ci=1024;
const int &rci = ci;
rci =42; //error
用const引用来引用non-const值,这样可以修改原值,导致cosnt引用的结果也会改变。但同样的问题,不能修改const引用的结果。
int i=43;
const int &ri=i;
ri=10; //error
i =10; //ok
(3)指针指定为const
用法和引用相同,用const指针来指向non-const值,这样可以修改原值:
int m=10;
const int* ptr = &m; //ok, const pointer to non-const varible
m = 20; //ok
4.3 为什么要使用常引用?
如果既要利用引用提高程序的效率,又要保护传递给函数的数据不在函数中被改变,就应使用常引用。
4.4 什么是顶层常量和底层常量?
使用const修饰指针时,指针的属性有两种状态:const int *,int * const状态很容易混淆。在复制时,顶层常量可以被忽略,而底层常量会被限制:
int i = 0;
int * const p1 = &i; //顶层const
int *x = p1; // 正确,可以忽略p1的顶层const
int n = *p1; // 正确
int i = 0;
const int * p1 = &i; //底层const
int *x = p1; // 错误,*x不具备底层const资格
const int *x2 = p1; // 正确,具备底层const资格
4.5 类的成员函数使用const
前面使用const 表示返回值为const;后面加 const表示函数不可以修改class的成员。
const int FunctionConst::getValue(){
return value;//返回值是 const, 使用指针时很有用.
}
int FunctionConst::getValue2() const{
//此函数不能修改class FunctionConst的成员函数 value
value = 15;//错误的, 因为函数后面加 const
return value;
}
如果返回值是指针时,前面使用const可以防止函数调用表达式作为左值,使得指针的内容被修改。
5.类与对象
5.1 类和结构体区别
- class
- class 是引用类型,它在堆中分配空间,栈中保存的只是引用
- 默认是private
- struct
- struct 是值类型,它在栈中分配空间
- 默认是public
5.2 构造函数中const和引用的初始化
class A{
public:
A(int ii);
private:
int i;
const int ci;
int& ri;
}
A::A(int ii){
i = ii; //ok
ci = ii; //error;
ri = ii; //error
}
const和引用的初始化必须在创建的时候就要完成,所以我们需要用列表初始化:
A::A(int ii):i(ii),ci(ii),ri(i){}
5.3 静态成员
静态成员不属于任何一个实例化的对象。假如我们有一个银行账户类,每天的利率是一个统一的数值,我们不需要为每个账户都去设置,只需要设置一个静态成员,让所有账户share就行。
由于静态成员独立于实例化对象之外存在,对于静态成员函数来说,他们没有this指针。
静态成员在类外可以使用两种办法访问:
作用域符,
r=Account::rate();传统办法(对象,引用,类指针)
Account ac1; Account ac2; r=ac1.rate(); r=ac2->rate();
在类间可以直接访问。
由于静态成员不属于任何一个对象,所以构造函数对他是无效的,我们要初始化一个静态成员得通过函数在类外进行初始化。

使用constexpr或者const可以让他在类间初始化:
class Account
{
public:
static double rate() { return interestRate; }
static void rate(double);
private:
static constexpr int period = 30;// period is a constant
}
5.4 类的特殊成员函数
有5个:拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符、析构函数。
拷贝函数的定义:第一个参数是类的引用
class Foo{
public:
Foo();//default
Foo(Foo const&);//copy
}
拷贝赋值运算符:本质是重载了=运算符,运算符重载可以理解为:返回类型,函数名称,传入参数。赋值运算符通常应该返回一个指向其左侧对象的引用
class Foo{
public:
Foo& operator=(Foo const&);
}
析构函数:析构时会先执行函数体,成员销毁时时按照生成时的逆序发生的。析构时,先调用派生类析构函数,再调用基类.
class A{
public:
int i;
A(int const& _i) :i(_i) {}
~A(){
cout << i;
}
};//先输出i,再销毁
5.5 析构函数注意事项
如果要自定义析构,则必须自定义拷贝和赋值。主要是针对浅拷贝和深拷贝的问题。
//深拷贝
HasPtr& operator=(HasPtr const& rhs){
this->ps = new size_t[num];
this->num = rhs.num;
for(int i=0;i<num;i++)
this->ps[i]=rhs.ps[i];
return this*;
}
//浅拷贝
HasPtr& operator=(HasPtr const& rhs){
this->num=rhs.num;
this->ps = rhs.ps;
return this*;
}
由于两个指针指向同一片内存区域,如果其中一个被释放,则另一个变成野指针。用智能指针可以避免:
int* p1 = new int(5);
int* p2 = p1;
delete p1; //野
shared_ptr<int> p3 = make_shared<int>(5);
auto p4 = p3;
p3.reset();//ok
5.6 合成构造函数
当我们只是传入了一个类的对象,编译器会帮助我们利用这个对象进行合成构造,具体如下:
class Sales_data{
public:
Sales_data(const Sales_data&);
private:
std::string bookNo;
int units_sold = 0;
double revenue = 0.0;
};
//与Sales_data的合成拷贝构造函数等价
Sales_data::Sales_data(const Sales_data &orig) :
bookNo(orig.bookNo), //使用string的拷贝构造函数
units_sold(orig.units_sold), //拷贝orig.units_sold
revenue(orig.revenue) //拷贝orig.revenue
{}
}
5.7 default和delete
使用关键词default以后可以显示地让编译器生成合成构造函数。delete可以禁用某些特殊成员函数。
比如比如Iostream类就不希望有多个对象访问IO相同的IO口。因此我们呢使用=delete禁用拷贝构造和赋值运算符。
5.8 如何区分移动和拷贝的重载?
方法1,利用const
void push_back(X const&);
void push_back(X&&);
方法2,利用引用限定符
class Foo{
public:
void sorted()&& {cout << "&&"<<endl;}
void sorted()& {cout << "&" << endl;}
};
Foo&& retVal(){
Foo f;
return std::move(f);
}
Foo& retFoo(){
Foo f;
return f;
}
int main(){
retVal().sorted(); //&&
retFoo().sorted(); //&
}
5.9 this指针
它指向当前对象,通过它可以访问当前对象的所有成员。
void Student::setname(char *name){
this->name = name;
}
5.10 访问私有成员的办法
- 类的成员函数访问
- 友元函数
6. 面向对象
6.1 oop特征
三大特征:封装、继承、多态
- 封装:分离接口和实现过程
- 继承:应用类之间的相似性
- 多态:函数复用
6.2 虚函数
虚函数并不是不实现,纯虚函数virtual void foo()=0;才是不实现(比如shape类中,我实在不想写area的表达过程,就让他成为纯虚函数,方便格式统一)。虚函数主要是用来简便地实现多态的,核心理念就是通过基类访问派生类定义的函数。
多态分两种:
- 编译时多态,重载
- 运行时多态,重写(重写是子类对父类的允许访问的方法的实现过程进行重新编写)
当API不会知道实际传进来的指针或引用是哪个类型时,先用一个基类接一下传进来的指针,在运行时根据类型安排虚函数执行。
class BaseItem {
public:
virtual void itemMethod()=0;
};
class ItemA :public BaseItem { public:void itemMethod() override { cout << "ItemA"<<endl; } };
class ItemB :public BaseItem { public:void itemMethod() override { cout << "ItemB" << endl; } };
class ItemC :public BaseItem { public:void itemMethod() override { cout << "ItemC" << endl; } };
int main(){
vector<shared_ptr<BaseItem>> ItemCollection;
shared_ptr<BaseItem> p;
//基类指针指向派生类!
p.reset(new ItemA());
ItemCollection.push_back(p);
p.reset(new ItemB());
ItemCollection.push_back(p);
p.reset(new ItemC());
ItemCollection.push_back(p);
for (auto it : ItemCollection) {
it->itemMethod();
}
}
C++11中允许使用override关键词显式注明虚函数的重写,如果重写失败就报错(不加的话会误以为一个新函数)(IDE推荐使用override)
struct B{
virtual void f1(int) const;
virtual void f2();
void f3();
};
struct D1 : B {
void f1(int) const override; // ok: f1 matches f1 in the base
void f2(int) override; // error: B has no f2(int) function
void f3() override; // error: f3 not virtual
}
6.3 虚函数表
当上行转换时(从派生类到基类)可以通过隐式转化或static_cast完成,但要完成下行转化就需要借助dynamic_cast。虚函数表的作用就是完成上下行转换,实现动态绑定。
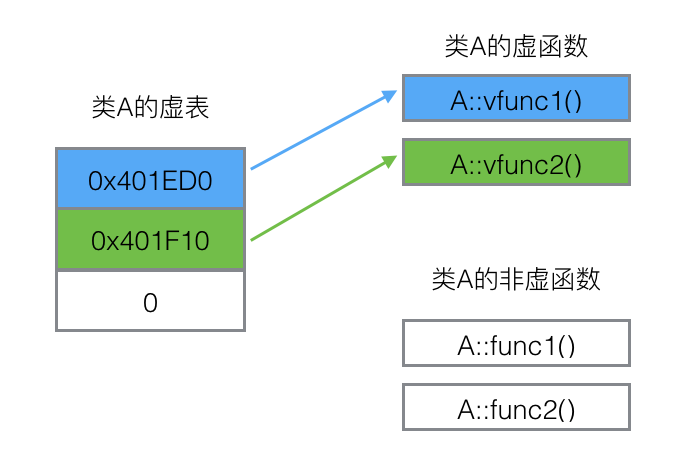
每一个包含虚函数的类(不是对象)都有一个自己的虚表
class A {
public:
virtual void vfunc1();
virtual void vfunc2();
void func1();
void func2();
private:
int m_data1, m_data2;
};
虚表是一个指针数组,其元素是虚函数的指针,每一个元素对应一个虚函数(普通函数不需要经过虚表)。
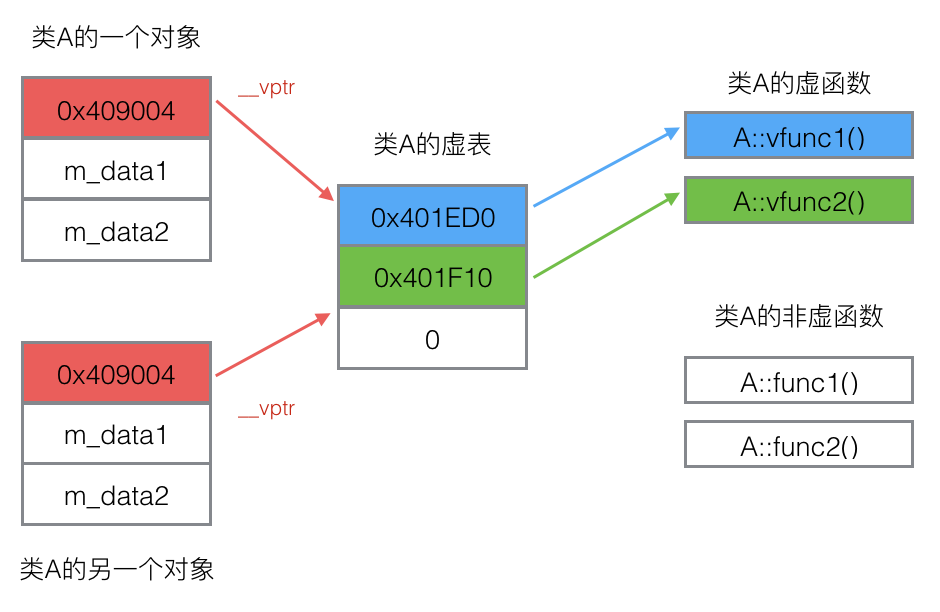
当某个类生成一个对象时,编译器在类中就添加了一个指针*_vptr,指向虚表
虚表是如何实现动态绑定的呢?
class A {
public:
virtual void vfunc1();
virtual void vfunc2();
};
class B : public A {
public:
virtual void vfunc1();
};
class C: public B {
public:
virtual void vfunc2();
};
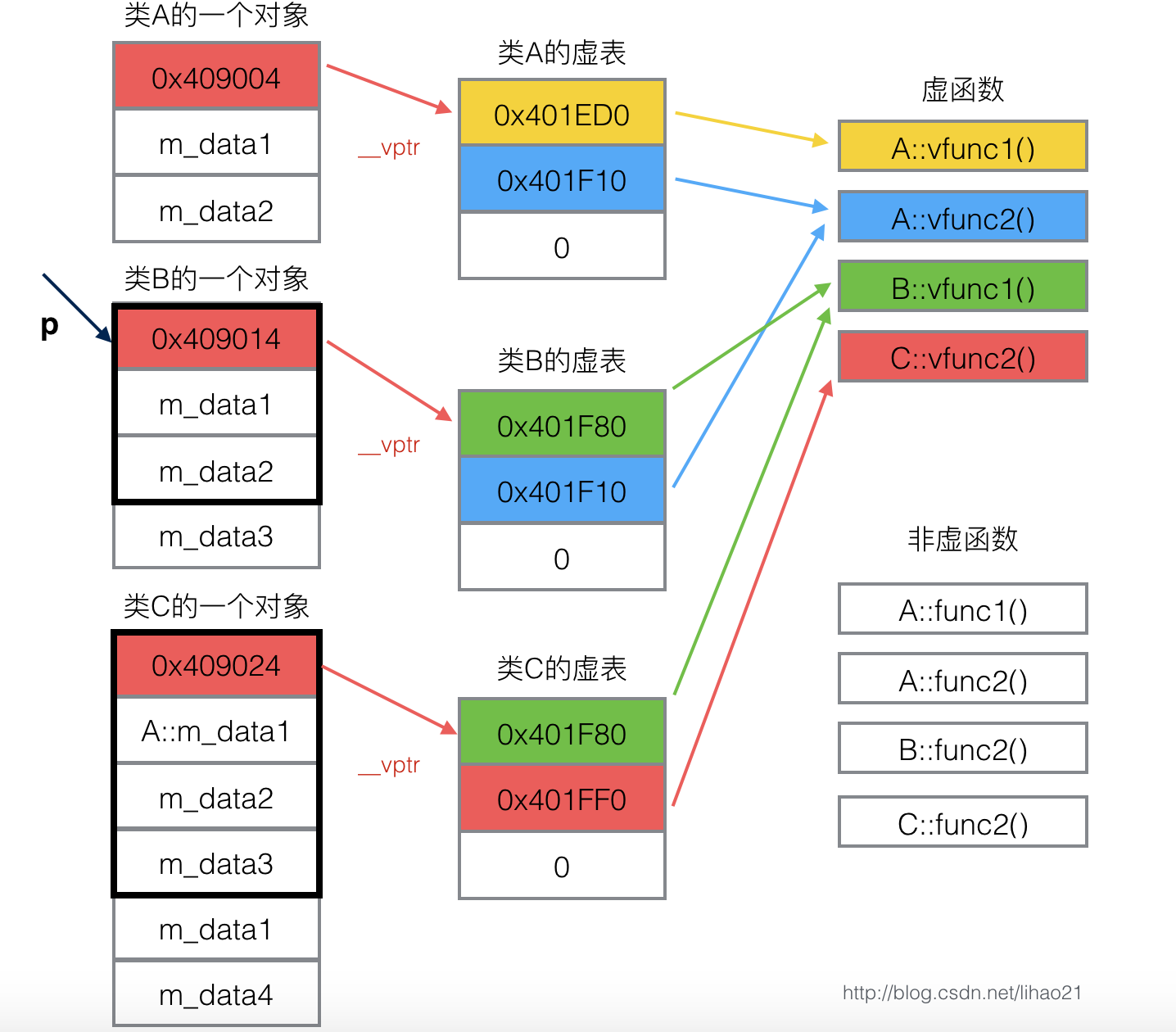
当我们调用的时候:
B bObject;
A* p = &bObject;
p->vfunc1(); //调用B::vfunc1();
程序在执行p->vfunc1();时,我们检查了三大条件:
- 对象是指针或引用形式
- 静态类型和动态类型不同
- 带虚函数的继承体系
所以现在动态类型现在生效。此时,并没有将p完全变为A,而是保留了B的虚函数表,所以我们调用的时候还是按B的虚函数表索引!