1. 回环检测概述
随着时间的推移,机器人的运动轨迹的误差会逐渐加大,一般情况下我们只能做到相邻帧之间的约束$xk,x{k-1}$,我们希望构建一些时间间隔更久远的约束:比如$x1-x{100}$之间的位姿关系。产生这种约束的原因是:我们察觉到相机经过了同一个地方,采集到了相似的数据。
现在问题在于,如何相机如何判断自己经过了同一地方。在解决这个问题之前,我们先引入一个概念:

回环检测的结果分为如上图所示的四种:TP FP FN TN。如下图所示图1不是回环,但由于太过相似被误认为回环,图2是回环但由于光线变化所以没有被检测出来。

我们可以定义两个统计量:正确率和召回率(Precision & Recall)
正确率的意思是:当算法认为它是回环时,它真的是回环的概率是多大;召回率的意思是:对于一个事实上的回环,算法检测出的概率是多大。这两者一般是矛盾的:
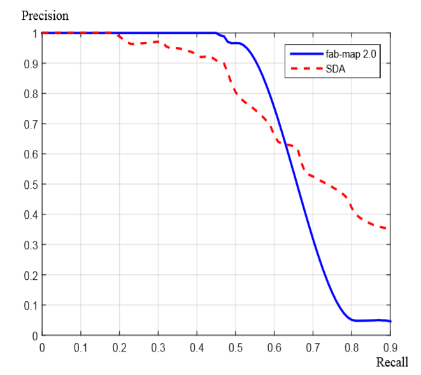
当检测条件宽松时,召回率会上升,但准确率会下降。好的算法在较高召回率的情况下也能保证好的准确率。通常情况下,SLAM选择高准确率,适当放弃一些召回率,为了保证不会出现较大的错误可以牺牲一些精确度。
2. 词袋模型
如何确定两张图具有相似性,从而判断此处为回环是非常关键的技术。一般来说我们可以任意选取两张图做特征匹配,但这样时间复杂度太高。我们可以借鉴数据结构中字典结构中的键值映射的思路。
词袋,也就是 Bag-of-Words(BoW),目的是用“图像上有哪几种特征”来描述一个图像。它所使用的数据结构是背包模型,也就是没有顺序的容器。假设一张图中发现了“人、车、狗”这三个对象,我们就可以把他们记录为单词$w_1,w_2,w_3$,在另一张图中只发现了“人、车”这两个单词,所以:
直接可以表示为$[1,1,0]^T$,当然也可以考虑出现的个数这样就不是二进制表示了$[2,1,0]^T$,因此我们只需要比较两张图的词袋的一范数(绝对值之和),就可以判断他们的相似性。
3. 字典模型
3.1 创建字典
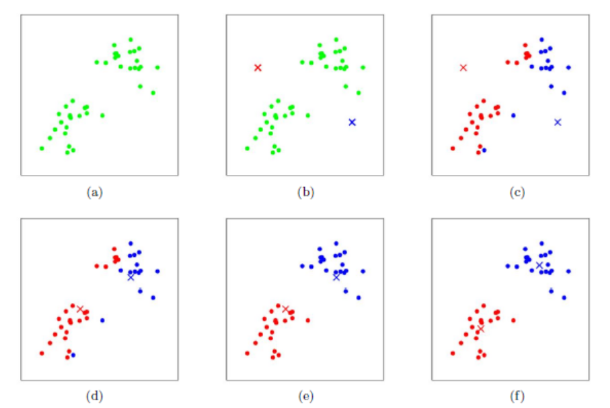
按照前面的介绍,字典由很多单词组成,而每一个单词代表了一个概念。一个单词与一个单独的特征点不同,它不是从单个图像上提取出来的,而是某一类特征的组合。所以,字典生成问题类似于一个聚类(Clustering)问题。
首先,假设我们对大量的图像提取了特征点,比如说有 N 个。现在,我们想找一个有 k 个单词的字典,每 个单词可以看作局部相邻特征点的集合,应该怎么做呢?这可以用经典的 K-means(K均值)算法解决。步骤如下:
- 随机选取k个中心点;
- 对每个样本计算他们与中心点的距离,取最小距离为归类;
- 重新计算每个类的中心点;
- 如果中心点的变化很小则算法收敛,退出;否则返回2
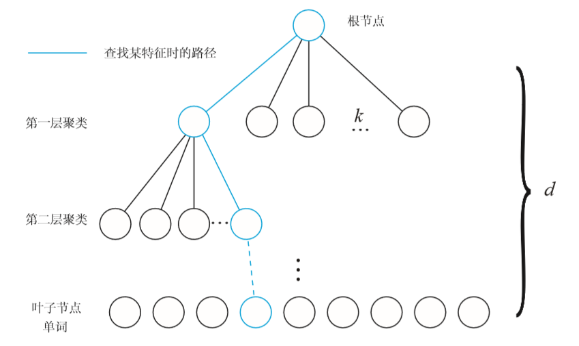
根据 K-means,我们可以把已经提取的大量特征点聚类成一个含有k个单词的字典了。现在的问题,变为如何根据图像中某个特征点,查找字典中相应的单词? 一般使用K叉树,步骤是:
- 在根节点,用k-means将所有样本聚成k类
- 对上层的每个父节点,把属于该节点的样本再次聚成k类,得到下一层。
- 以此类推,最后得到叶子层,也就是所谓的单词。
词袋模型利用视觉词典(vocabulary)来把图像转化为向量。过程如下:
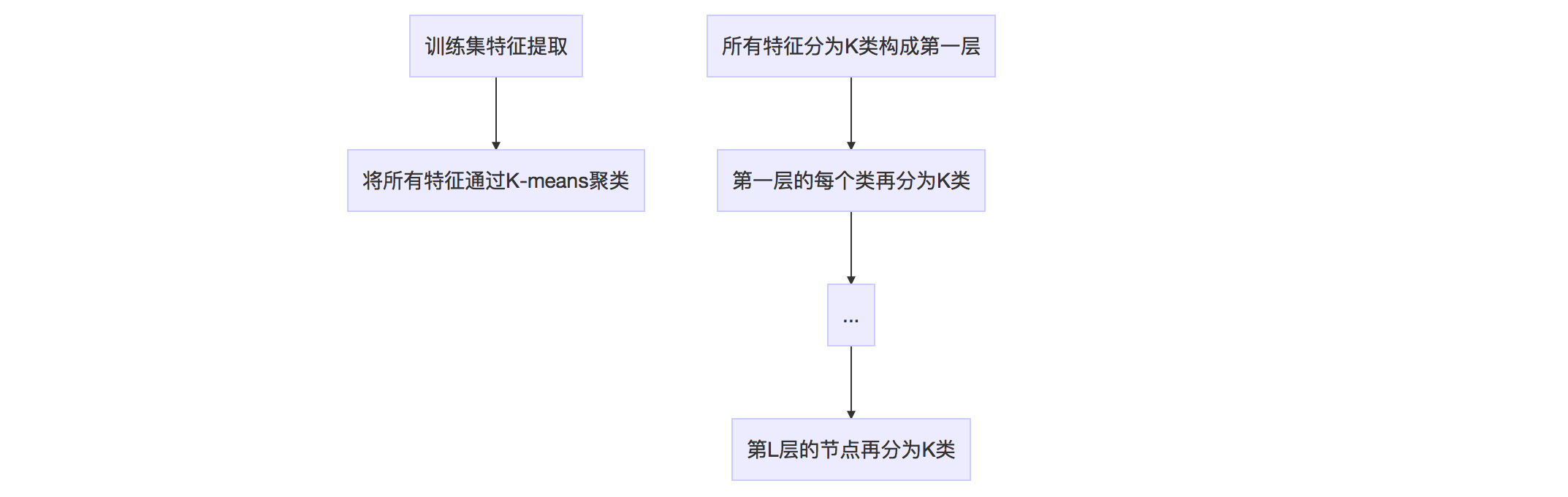
这棵树里面总共有$1+K+\cdots+K^L=(k^{L+1}-1)/(K-1)$个节点,所有叶节点在L层形成$W=K^L$类,每一类用该类中所有特征的平均特征(meanValue)作为代表,称为单词(word)。每个叶节点被赋予一个权重。常见的权重有TF、IDF、TF-IDF等
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是TF * IDF,TF代表词频(Term Frequency),表示词条在文档d中出现的频率。IDF代表逆向文件频率(Inverse Document Frequency)。如果包含词条t的文档越少,IDF越大,表明词条t具有很好的类别区分能力。
视觉词典可以通过离线训练大量数据得到。训练中只计算和保存单词的IDF值,即单词在众多图像中的区分度。TF则是从实际图像中计算得到各个单词的频率。单词的TF越高,说明单词在这幅图像中出现的越多;单词的IDF越高,说明单词本身具有高区分度。二者结合起来,即可得到这幅图像的BoW描述。
3.2 特征识别应用
离线生成视觉词典以后,我们就能在线进行图像识别或者场景识别。实际应用中分为两步进行:
为图像生成一个表征向量$v_{1×W}$,图像中的每个特征都在词典中搜索其最近邻的叶节点。所有叶节点上的权重集合构成了BoW向量$v$
根据BoW向量,计算当前图像和其它图像之间的距离:
在视觉词典之上,引入了正向索引(direct index)和反向索引(inverse index)的概念。
用反向索引记录每个叶节点对应的图像编号。当识别图像时,根据反向索引选出有着公共叶节点的备选图像并计算得分,而不需要计算与所有图像的得分。
比如下面三张图包含了一些特征:
- imageA:cat, dog, panda
- imageB: cat
- imageC::cat,dog
那么就会得到以下反向文件索引:
- dog : { A, C }
- cat:{ A, B , C}
- panda:{ A }
当新得到一张图片D,它包含了cat和dog,则对应集合$(A,B)\cap(A,B,C)=(A,B)$所以图片D和图片C最像。
而正排索引非常慢。