主要介绍C++11/14里面的新东西,分为两个篇章,这一篇章介绍五个特性:初始化方式,nullptr,别名using,限定域枚举,deleted函数。
Item 7:Distinguish between () and {} when creating objects
大体上来说,C++的初始化方式分为三种:
int x(0);
int y = 0;
int z{0}; //等价于int c={0};
对于int这种内置类型来说,他们的区别并没有太大的意义,而对于用户自定义的类型而言,区别赋值运算符和初始化就非常重要了。
Widget w1; //调用默认构造函数
Widget w2 = w1; //不是赋值运算符,调用拷贝构造函数
w1 = w2; //是一个赋值运算符,调用operator=函数
为了整合这些混乱的初始化方式,C++11引入了统一初始化(uniform initialization),实现的办法是使用花括号!具体来说有四个好处:
(1)类中非静态成员指定默认初始值
括号初始化也能被用于为非静态数据成员指定默认初始值。C++11允许”=”初始化也拥有这种能力:
class Widget{
...
private:
int x{0}; //没问题,x初始值为0
int y = 0; //同上
int z(0); //错误!
}
(2)用于不可拷贝对象初始化
std::atomic(原子化操作)是不可拷贝对象,所以不能用=初始化!
std::atomic<int> ai1{0}; //没问题,x初始值为0
std::atomic<int> ai2(0); //没问题
std::atomic<int> ai3 = 0; //错误!
(3)避免变窄转换(narrowing conversion)
double x,y,z;
int sum1{x+y+z}; //错误
int sum2(x + y +z); //可以(表达式的值被截为int),损失精度
int sum3 = x + y + z; //同上,损失精度
(4)避免语法解析歧义
尝试使用一个没有参数的构造函数构造对象,它就会变成函数声明:
Widget w2(); //最令人头疼的解析!声明一个函数w2,返回Widget
由于函数声明中形参列表不能使用花括号,所以使用花括号初始化就可以消除这种歧义:
Widget w3{};//调用没有参数的构造函数构造对象
但是使用花括号统一初始化一个大毛病!std::initializer_list误匹配!
class Widget {
public:
Widget(int i,bool b);
Widget(int i,double b);
Widget(std::initializer_list<long double> il);
};
Widget(10,true); //调用的是第一个构造函数,
Widget{10,true}; //按理应该是调用第一个构造函数,但是现在却调用了带初始化列表的构造函数
这是因为编译器热衷于把花括号初始化与使std::initializer_list构造函数匹配,热衷程度甚至超过了最佳匹配。比如:
class Widget {
public:
Widget(int i, bool b);
Widget(int i, double d);
Widget(std::initializer_list<bool> il);
…
};
Widget w{10, 5.0}; //错误!要求变窄转换
当然出现这样的问题主要还是因为统一初始化是允许宽化转换的,所以上面的上面10和true都转换成long double了。而上面那个10和5.0转化到bool是窄式转化,这是不允许的!
只有当没办法把括号初始化中实参的类型转化为std::initializer_list时,编译器才会回到正常的函数决议流程中。比如下面的string就是如此。
class Widget {
public:
Widget(int i, bool b);
Widget(int i, double d);
Widget(std::initializer_list<std::string> il);
…
};
Widget w1(10, true);// 使用小括号初始化,调用第一个构造函数
Widget w2{10, true};// 使用花括号初始化,调用第一个构造函数
Widget w3(10, 5.0);// 使用小括号初始化,调用第二个构造函数
Widget w4{10, 5.0};// 使用花括号初始化,调用第二个构造函数
这个毛病会造成某些时候括号和花括号不同语义。std::vector有一个非std::initializer_list构造函数允许你去指定容器的初始大小,以及使用一个值填满你的容器。但它也有一个std::initializer_list构造函数允许你使用花括号里面的值初始化容器。令人头疼!
std::vector<int> v1(10, 20); //使用非std::initializer_list
//构造函数创建一个包含10个元素
//所有的元素的值都是20
std::vector<int> v2{10, 20}; //使用std::initializer_list
//构造函数创建包含两个元素的std::vector
//元素的值为10和20
总的来说,为了避免这些问题,那么作为库的开发者你应该把你的构造函数设计为不管用户是小括号还是使用花括号进行初始化都不会有什么影响(避免vector设计的睿智操作);作为库的使用者必须认真的在花括号和小括号之间选择一个来创建对象。大多数开发者都使用其中一种作为默认情况,只有当他们不能使用这种的时候才会考虑另一种。
Item 8: Prefer nullptr to 0 and NULL.
废话不多说,直接说好处:
(1)使用nullptr*代替0和NULL可以避开那些烦人的函数重载决议
NULL最大的问题在于它没有明确的类型。
void f(int); //三个f的重载函数
void f(bool);
void f(long);
void f(void*);
f(NULL); //可能会不通过,也可能会调用int,但不会调用void*
f(NULL)的不确定性是由于NULL的实现不同造成的,在我的编译环境下(Visual Studio 2019),NULL被划定为int型。这样的话,调用就具有二义性!
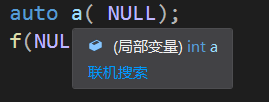
现在做一个实验:注释掉int的重载类型,发现

这是因为缺失了int类型的重载,它会开始转化,而从int到long, bool, void\*的转换都会被考虑。同理,调用f(0)也会出现这样的状况。
为了避免二义性,准确地定位到void\*,推荐使用nullptr!
nullptr的类型是std::nullptr_t,这种类型的特点是可以转换为指向任何内置类型的指针,这也是为什么把它叫做通用类型的指针。
(2)和auto共用时,让代码更加明确
如果你不知道findRecord返回了什么(或者不能轻易的找出),那么你就不太清楚到底result是一个指针类型还是一个整型。
auto result = findRecord( /* arguments */ );
if (result == 0) {
…
}
因此,我们最好改为:
auto result = findRecord( /* arguments */ );
if (result == nullptr) {
…
}
(3)模板中有更好兼容性
假如有一些函数只能被合适的已锁互斥量调用。每个函数都有一个不同类型的指针:
int f1(std::shared_ptr<Widget> spw); // 只能被合适的已锁互斥量调用
double f2(std::unique_ptr<Widget> upw);
bool f3(Widget* pw);
我们用模板:
template<typename FuncType,typename MuxType,typename PtrType>
decltype(auto) lockAndCall(FuncType func,
MuxType& mutex,
PtrType ptr) {
MuxGuard g(mutex);
return func(ptr);
}
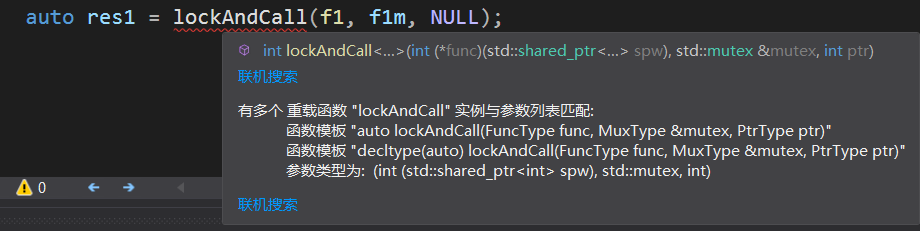
可以写这样的代码调用lockAndCall模板:
auto result1 = lockAndCall(f1, f1m, 0); // 错误!
auto result2 = lockAndCall(f2, f2m, NULL); // 错误!
auto result3 = lockAndCall(f3, f3m, nullptr); // OK
为什么会出现错误呢?还是老毛病:0和NULL都是int型(至少在我的编译环境下是),但我们期待的参数是std::shared_ptr,所以推导的过程中就会发生错误。
Item 9:Prefer alias declarations to typedefs
C++常常为复杂的类型做一个重定义,方式有两种:typedef和using使用别名。前者是98的东西,后者是11提供的新东西。
typedef std::unique_ptr<std::unordered_map<std::string, std::string>> UPtrMapSS;
using UPtrMapSS = std::unique_ptr<std::unordered_map<std::string, std::string>>;
具体来说使用using别名有这么几个好处:
// FP是一个指向函数的指针的同义词,它指向的函数带有int和const std::string&形参,不返回任何东西
typedef void (*FP)(int, const std::string&); // typedef
//同上
using FP = void (*)(int, const std::string&); // 别名声明
(2)方便使用模板
typedef没有办法在模板声明的作用域中做类型重定义,必须放在一个自定义类型作用域内,而using没有这个限制。
template<typename T>
struct MyAllocList {
typedef std::list<T, MyAlloc<T>> type;
};
MyAllocList<Widget>::type lw;
而using没有这个限制。
template<typename T>
using MyAllocList = std::list<T,MyAlloc<T>>;
MyAllocList<Widget> lw;
对于嵌套类型来说,typedef需要使用typename
template<typename T>
struct MyAllocList {
typedef std::list<T, MyAlloc<T>> type;
};
template<typename T>
class Widget {
private:
typename MyAllocList<T>::type list;
…
};
由于MyAllocList::type使用了一个类型,它依赖于模板参数T,因此它是一个依赖类型,依赖类型就必须在前面加上typename。
相反,使用using就不会有问题。对你来说,MyAllocList(使用了模板别名声明的版本)可能看起来和MyAllocList::type(使用typedef的版本)一样都应该依赖模板参数T,但编译器和你想的不同。
当编译器处理MyAllocList(使用模板别名声明的版本),它们知道MyAllocList是一个类型名,它一定是一个类型名。因此MyAllocList就是一个非依赖类型,就不要求必须使用typename。
Item 10:Prefer scoped enums to unscoped enums.
首先介绍一下枚举:
打开一个文件可能有三种状态:input, output和append. 典型做法是,对应定义3个常数,即:
const int input = 1;const int output = 2;const int append = 3;
然后,调用以下函数:bool open_file(string file_name, int open_mode);问题是可能用户手贱输了一个4进去,超出范围,这就很麻烦了,而且纯数字也不好记忆和分辩。通过枚举可以解决这个问题。
enum open_modes {input = 1, output, append}; open_file("Phenix_and_the_Crane", append);
C++的枚举分为两种:有限定域的枚举和无限定域枚举,前者是11的新特性,后者是98的特性。推荐使用有限定域的枚举,理由如下:
(1)防止污染命名空间
通常来说我们在花括号中定义的名称其作用域就在花括号中,但是C++98的枚举类型的声明却不遵从这个规则。
enum Color {black,white,red};
auto white = false; //编译出错white已经声明了
在11中,我们通过使用enum class关键词就可以声明限定域枚举,避免泄露枚举名:
enum class Color { black, white, red }; // black, white, red
// 限制在Color域内
auto white = false; // 没问题,同样域内没有这个名字
Color c = white; // 错误,这个域中没有white
Color c = Color::white; // 没问题
auto c = Color::white; // 也没问题(也符合条款5的建议)
(2)避免隐式转化
void primeFactors(std::size_t x) { return; }
enum Color { black, white, red }; // 未限域枚举
Color c = red;
if (c < 3.5) { //int和double比较,玩蛇?
primeFactors(c); // int强转编程size_t,终极玩蛇?
}
虽然这些操作在玩蛇,但编译器依然将他们通过,这可能会造成不好的结果,所以我们倾向于使用限域枚举,上面的玩蛇操作都不会通过编译!如果真的很想进行转化,使用强转符号。
if (static_cast<double>(c) < 14.5) { // 奇怪的代码,但是有效
auto factors =primeFactors(static_cast<std::size_t>(c)); // 能通过编译
}
(3)支持前项声明
先解释一下前项声明:
前向声明(Forward Declaration)是指声明标识符(表示编程的实体,如数据类型、变量、函数)时还没有给出完整的定义。下面就是一个函数前向声明的例子。
void printThisInteger(int);
...
void printThisInteger(int x) {
printf("%d\n", x);
}
使用未限定域枚举前向声明会发生错误:
enum Color; // 错误!
enum class Color; // 没问题
原因是unscoped枚举类型的实际类型并不是enum,它有一个底层存储类型。而这个底层存储类型是编译器在编译的时候决策的,根据你的取值范围来定义你的底层存储类型。
enum Color { black, white, red }; //编译器选择char型,因为只有三个值
enum Status { good = 0, //编译器选择int或long,因为范围比较大
failed = 1,
incomplete = 100,
corrupt = 200,
indeterminate = 0xFFFFFFFF
};
可以看到,由于类型未定,所以不能前置声明,这就带来一个问题:编译依赖过强!换句话说,整个枚举类作用于整个系统,我新添加一个成员,就会导致全部重新编译。
enum class Status; // forward declaration
void continueProcessing(Status s); // use of fwd-declared enum
即使Status的定义发生改变,包含这些声明的头文件也不会重新编译,如果它只是添加一个枚举名。continueProcessing也不会受影响,因为他不涉及新添加的枚举。
enum class Color;
int foo(Color c);
//修改成员后,上面的部分都不用管
enum class Color {red,black};
int foo(Color red) { return 1; }
void main()
{
Color r = Color::red;
cout << foo(r) << endl;
}
但是,使用限定域枚举有的时候反而会加大工作量!
比如在社交网站中,假设我们有一个tuple保存了用户的名字,email地址,声望点:
using UserInfo = // 类型别名,参见Item 9
std::tuple<std::string, // 名字
std::string, // email地址
std::size_t> ; // 声望
UserInfo uInfo; // tuple对象
auto val = std::get<1>(uInfo); // 获取第一个字段
这里先说明一下tuple:
std::tuple是类似pair的模板。每个pair的成员类型都不相同,但每个pair都恰好有两个成员。不同std::tuple类型的成员类型也不相同,但一个std::tuple可以有任意数量的成员。要访问一个
tuple的成员,就要使用一个名为get的标准库函数模板。get尖括号中的值必须是一个整型常量表达式。与往常一样,我们从0开始计数,意味着get<0>是第一个成员。
虽然注释说明了tuple各个字段对应的意思,但还是要记住第一个字段代表用户的email地址,这让人很不爽。我们可以使用非限定域枚举将名字和字段编号关联起来解决这个问题。
之所以它能正常工作是因为UserInfoFields中的枚举名隐式转换成std::size_t了,其中std::size_t是std::get模板实参所需的。
对应的限域枚举版本就很啰嗦了:
enum class UserInfoFields { uiName, uiEmail, uiReputation };
UserInfo uInfo; // as before
…
auto val =
std::get<static_cast<std::size_t>(UserInfoFields::uiEmail)>
(uInfo);
Item 11:Prefer deleted functions to private undefined ones.
我们都知道,如果你写的代码不想别人使用,你可以将它声明为private,但在C++11以后,建议使用delete而不是private。delete的用法有三类:
(1)在类中防止某些函数调用
比如说,我们要防止拷贝istream和ostream。因为要进行哪些操作是模棱两可的。比如一个istream对象,代表一个输入值的流,流中有一些已经被读取,有一些可能马上要被读取。解决这个问题最好的方法是不定义这个操作。直接禁止拷贝流。
在98中是这样写的:
template <class charT, class traits = char_traits<charT> >
class basic_ios : public ios_base {
public:
…
private:
basic_ios(const basic_ios& ); // not defined
basic_ios& operator=(const basic_ios&); // not defined
};
在11中可以改为:
template <class charT, class traits = char_traits<charT> >
class basic_ios : public ios_base {
public:
…
basic_ios(const basic_ios& ) = delete;
basic_ios& operator=(const basic_ios&) = delete;
…
};
deleted函数不能以任何方式被调用,即使你在成员函数或者友元函数里面调用deleted函数也不能通过编译。
需要注意的是:deleted函数被声明为public而不是private。这也是有原因的。当客户端代码试图调用成员函数,C++会在检查deleted状态前检查它的访问性。当客户端代码调用一个私有的deleted函数,一些编译器只会给出该函数是private的错误。
(2)作用于非成员函数禁止调用
bool isLucky(int number);
C++有沉重的C包袱,使得含糊的、能被视作数值的任何类型都能隐式转换为int,但是有一些调用可能是没有意义的:
如果我们想幸运数必须是整数,就应该禁止通过这些编译:
bool isLucky(int number); // 原始版本
bool isLucky(char) = delete; // 拒绝char
bool isLucky(bool) = delete; // 拒绝bool
bool isLucky(double) = delete; // 拒绝float和double

(3)禁止一些模板实例化
在指针的世界里有两种特殊情况。一是void*指针,因为没办法对它们进行解引用,或者加加减减等。另一种指针是char*,因为它们通常代表C风格的字符串,而不是正常意义下指向单个字符的指针。这两种情况要特殊处理,在processPointer模板里面,我们假设正确的函数应该拒绝这些类型。
template<>
void processPointer<void>(void*) = delete;
template<>
void processPointer<char>(char*) = delete;