Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)来进行数据共享,并提供复制和故障转移功能。
1. 节点
1.1 节点是什么
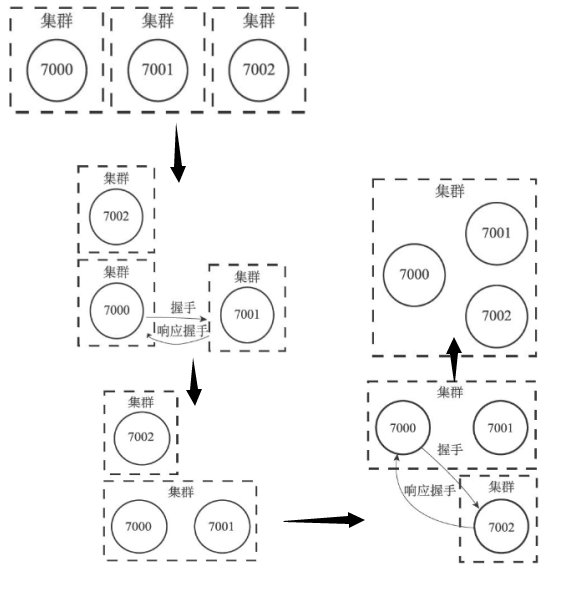
节点时Redis中数据存储的单位。一个Redis集群通常由多个节点(node)组成,在刚开始的时候,每个节点都是相互独立的,它们都处于一个只包含自己的集群当中,要组建一个真正可工作的集群,我们必须将各个独立的节点连接起来,构成一个包含多个节点的集群。
使用CLUSTER MEET命令来完成,该命令的格式如下:
CLUSTER MEET <ip> <port>
当前节点发送CLUSTER MEET命令,可以与ip和port所指定的节点进行握手(handshake),当握手成功时,node节点就会将ip和port所指定的节点添加到node节点当前所在的集群中。
1.2 启动节点
一个节点就是一个运行在集群模式下的Redis服务器,Redis服务器在启动时会根据cluster-enabled配置选项是否为yes来决定是否开启服务器的集群模式:

1.3 集群数据结构
clusterNode结构保存了一个节点的当前状态,比如节点的创建时间、节点的名字、节点当前的配置纪元、节点的IP地址和端口号等等。每个节点都会使用一个clusterNode结构来记录自己的状态,并为集群中的所有其他节点(包括主节点和从节点)都创建一个相应的clusterNode结构,以此来记录其他节点的状态:
struct clusterNode {
// 创建节点的时间
mstime_t ctime;
// 节点的名字,由 40 个十六进制字符组成
// 例如 68eef66df23420a5862208ef5b1a7005b806f2ff
char name[REDIS_CLUSTER_NAMELEN];
// 节点标识
// 使用各种不同的标识值记录节点的角色(比如主节点或者从节点),
// 以及节点目前所处的状态(比如在线或者下线)。
int flags;
// 节点当前的配置纪元,用于实现故障转移
uint64_t configEpoch;
// 节点的 IP 地址
char ip[REDIS_IP_STR_LEN];
// 节点的端口号
int port;
// 保存连接节点所需的有关信息
clusterLink *link;
// ...
};
clusterNode 结构的 link 属性是一个 clusterLink 结构, 该结构保存了连接节点所需的有关信息, 比如套接字描述符, 输入缓冲区和输出缓冲区:
typedef struct clusterLink {
// 连接的创建时间
mstime_t ctime;
// TCP 套接字描述符
int fd;
// 输出缓冲区,保存着等待发送给其他节点的消息(message)。
sds sndbuf;
// 输入缓冲区,保存着从其他节点接收到的消息。
sds rcvbuf;
// 与这个连接相关联的节点,如果没有的话就为 NULL
struct clusterNode *node;
} clusterLink;
假设现在有三个独立的节点127.0.0.1:7000、127.0.0.1:7001、127.0.0.1:7002,将他们创立为集群后,数据结构如下:
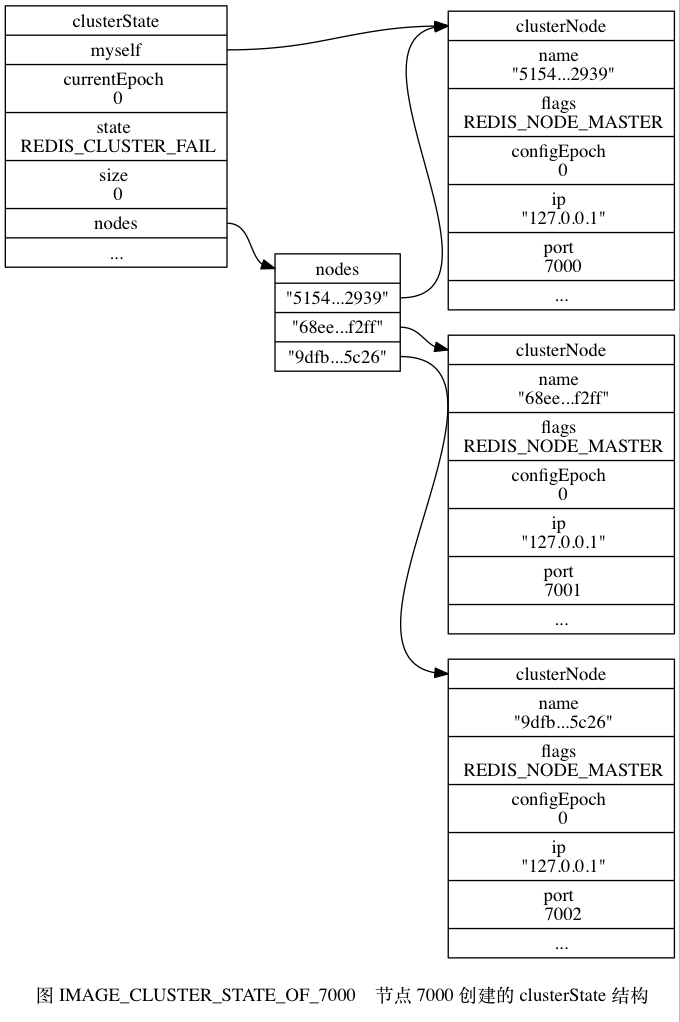
总的来说:
- clusterState保存集群状态,每个节点都保存着一个这样的状态,记录了它们眼中的集群的样子。
- clusterNode保存了某个节点的状态,同时通过指针指向其他节点,达到关联的目的
- clusterLink保存了和其他节点通信的信息。
1.4 实现CLUSTER MEET命令
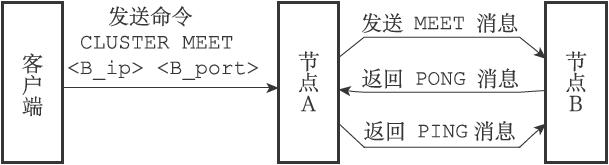
向A发送命令,希望A和B形成集群,则:
- 节点A会为节点B创建一个clusterNode结构,并将该结构添加到自己的
clusterState.nodes字典里面。 - 根据命令给定的IP和端口,节点A向B发送一条MEET消息
- B收到以后,为节点A创建一个clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。
- B向A返回一条PONG消息
- A收到PONG后向B返回一条PING
- B收到PING后,握手完成。
2. 槽指派
Redis集群通过分片的方式来保存数据库中的键值对:集群的整个数据库被分为16384个槽(slot),数据库中的每个键都属于这16384个槽的其中一个,集群中的每个节点可以处理0个或最多16384个槽。
当数据库中的16384个槽都有节点在处理时,集群处于上线状态(ok);相反地,如果数据库中有任何一个槽没有得到处理,那么集群处于下线状态(fail)。
换句话说,只有完全分配了16384个槽才会进入上线状态。
2.1 当前节点的槽指派信息
clusterNode结构的slots属性和numslot属性记录了节点负责处理哪些槽:
struct clusterNode
{
// ...
unsigned char slots[16384/8];
int numslots;
// ...
};
slots属性是一个二进制位数组(bit array),这个数组的长度为16384/8=2048个字节,共包含16384个二进制位。通过判断二进制的01状态来判断,此槽是否属于。
下图表示这个节点负责处理槽0至7,

因为数组自带索引,所以取出某个槽是否使用的时间复杂的为$O(1)$。
2.2 传播节点的槽指派信息
一个节点除了会将自己负责处理的槽记录在clusterNode结构的slots属性和numslots属性之外,它还会将自己的slots数组通过消息发送给集群中的其他节点,以此来告知其他节点自己目前负责处理哪些槽。
当节点A通过消息从节点B那里接收到节点B的slots数组时,节点A会在自己的clusterState.nodes字典中查找节点B对应的clusterNode结构,并对结构中的slots数组进行保存或者更新。
因此,集群中的每个节点都会知道数据库中的16384个槽分别被指派给了集群中的哪些节点。
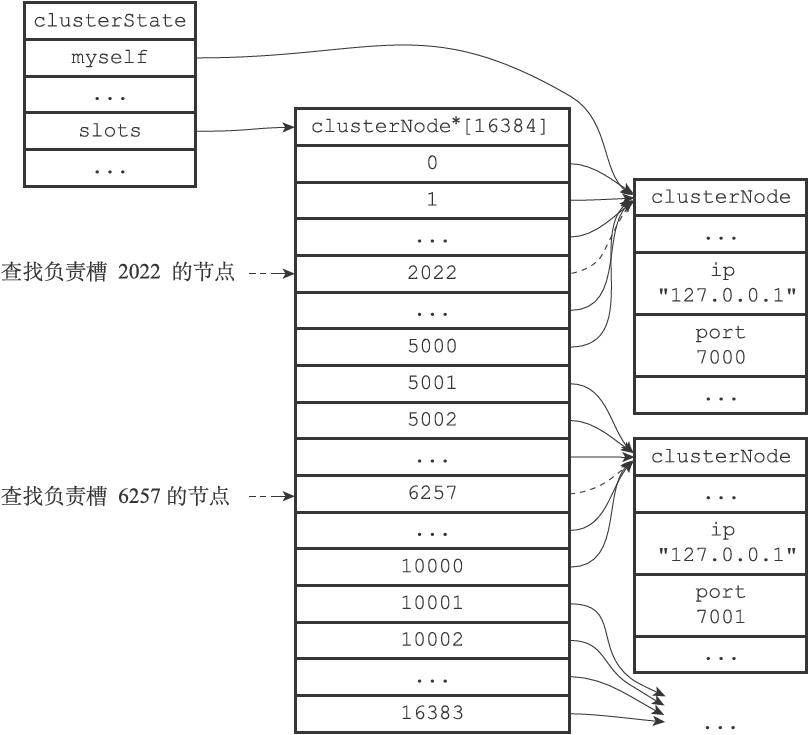
在clusterState中有一个myself指针,指向当前节点clusterNode,这个结构中包含了一个二进制数组,记录当前节点的槽指派情况。而clusterState中还有一个clusterNode *slots[REDIS_CLUSTER_SLOTS];,记录了其他节点的槽指派情况。例如 slots[i] = clusterNode_A 表示槽 i 由节点 A 处理
2.3 集群所有槽的指派信息
clusterState结构中的slots数组记录了集群中所有16384个槽的指派信息:
typedef struct clusterState
{
// ...
clusterNode *slots[16384];
// ...
} clusterState;
每个数组都是指向clusterNode结构的指针:
- 如果指向NULL,表示尚未指派给任何节点。
- 如果指向某一个clusterNode,则表示槽i指派给了某一个节点。
如果只将槽指派信息保存在各个节点的clusterNode.slots数组里,会出现一些无法高效地解决的问题,而clusterState.slots数组的存在解决了这些问题:
- 如果想知道某个槽是否被指派以及被指派给了谁,需要遍历所有clusterNode结构。
- 通过
clusterState保存的数组,可以以$O(1)$的时间取得结果。
2.4 槽的保存方式
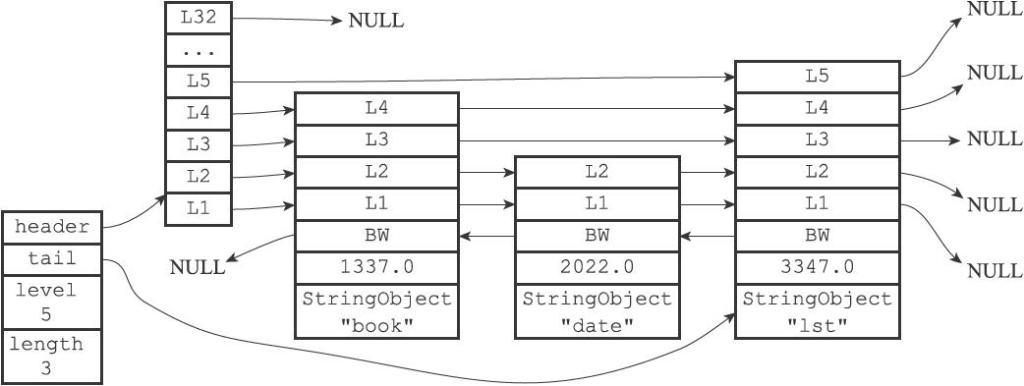
节点还会用clusterState结构中的slots_to_keys跳跃表来保存槽和键之间的关系:
typedef struct clusterState
{
// ...
zskiplist *slots_to_keys;
// ...
} clusterState;
slots_to_keys跳跃表每个节点的分值(score)都是一个槽号,而每个节点的成员(member)都是一个数据库键:
3. MOVED错误
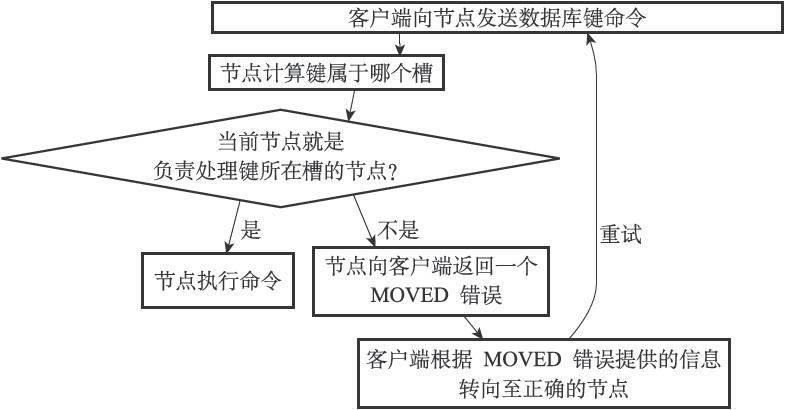
前面提到,指派完槽以后,集群会进入上线状态,此时客户端可以向集群中的节点发送数据命令。
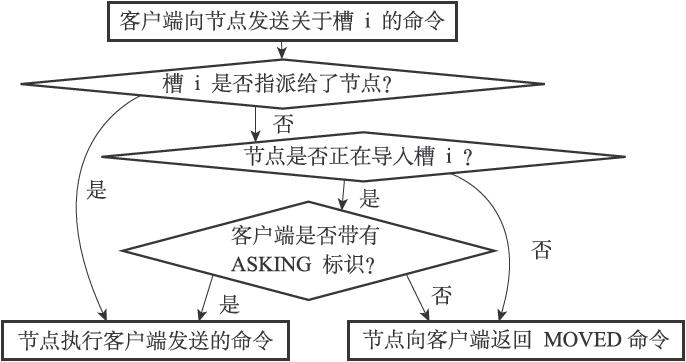
当客户端向节点发送与数据库键有关的命令时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己:
- 如果指派给自己,执行
- 否则,返回MOVED错误,并将客户端指向正确的节点。
比如,date键所在的槽正好是节点7000负责,正常执行。
127.0.0.1:7000> SET date "2013-12-31"
OK
如果是如下的情况,客户端会被自动转到正确的节点。
127.0.0.1:7000> SET msg "happy new year!"
-> Redirected to slot [6257] located at 127.0.0.1:7001
OK
127.0.0.1:7001> GET msg
"happy new year!"
要完成上面的操作,需要至少两步:
- 判断槽是否自己负责
- MOVED错误的实现方法
3.1 判断槽是否自己负责
键属于哪个槽需要用到CRC-16校验的办法:
slot_number = CRC16(key)&16383
这样就可以计算出一个介于0至16383之间的整数作为键key的槽号。
当节点计算出键所属的槽i之后,节点就会检查自己在clusterState.slots数组中的项i,判断键所在的槽是否由自己负责:
- 如果
clusterState.slots[i]等于clusterState.myself,那么说明槽i由当前节点负责,节点可以执行客户端发送的命令。 - 反之,则记下指向clusterNode结构所记录的IP和端口号
3.2 MOVED错误实现
MOVED错误的格式为:
MOVED <slot> <ip>:<port>
其中slot为键所在的槽,而ip和port则是负责处理槽slot的节点的IP地址和端口号。
当客户端接收到节点返回的MOVED错误时,客户端会根据MOVED错误中提供的IP地址和端口号,转向至负责处理槽slot的节点,并向该节点重新发送之前想要执行的命令。
127.0.0.1:7000> SET msg "happy new year!"
-> Redirected to slot [6257] located at 127.0.0.1:7001
OK


4. 重新分片
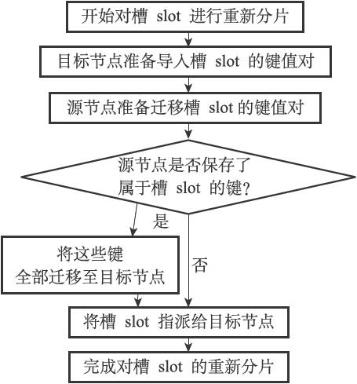
Redis集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点),并且相关槽所属的键值对也会从源节点被移动到目标节点。
重新分片操作可以在线(online)进行,在重新分片的过程中,集群不需要下线,并且源节点和目标节点都可以继续处理命令请求。
Redis集群的重新分片操作是由Redis的集群管理软件redis-trib负责执行的,Redis提供了进行重新分片所需的所有命令,而redis-trib则通过向源节点和目标节点发送命令来进行重新分片操作。
重新分配步骤如下:
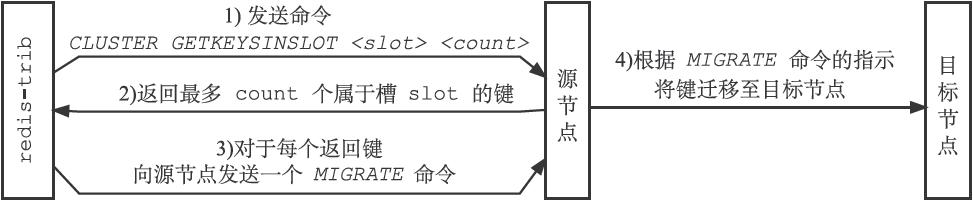
如果重新分片涉及多个槽,那么redis-trib将对每个给定的槽分别执行上面给出的步骤。
5. ASK错误
正在重新分片时,属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。
当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时:
- 槽在自己这里,执行客户端命令。
- 槽不在,返回ASK错误,指引客户端转向正在导入槽的目标节点。
下面讲解ASK错误的实现原理:
5.1 关键命令
(1)CLUSTER SETSLOT IMPORTING命令的实现
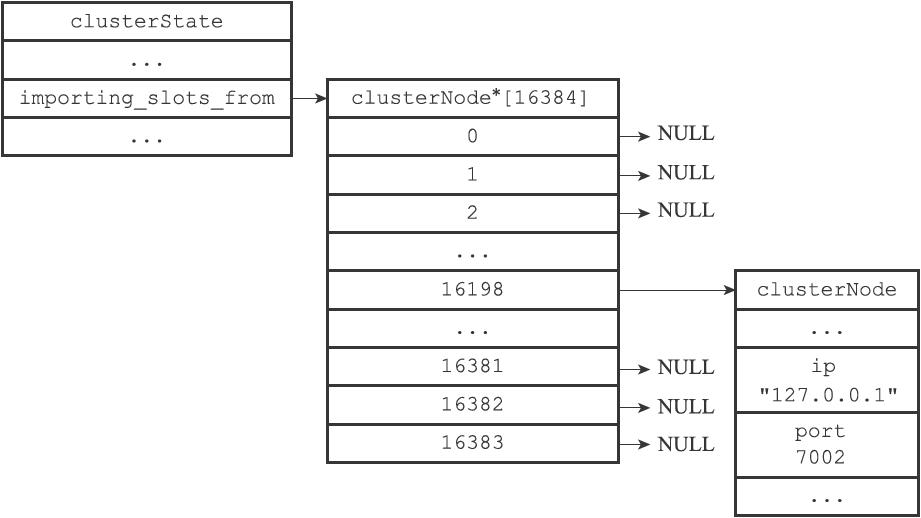
clusterState结构的importing_slots_from数组记录了当前节点正在从其他节点导入的槽:
typedef struct clusterState
{
// ...
clusterNode *importing_slots_from[16384];
// ...
} clusterState;
如果importing_slots_from[i]的值不为NULL,而是指向一个clusterNode结构,那么表示当前节点正在从clusterNode所代表的节点导入槽i。
在对集群进行重新分片的时候,向目标节点发送命令:
CLUSTER SETSLOT <i> IMPORTING <source_id>
假如,客户端向节点7003发送命令:
# 9dfb... 是节点7002 的ID
127.0.0.1:7003> CLUSTER SETSLOT 16198 IMPORTING
9dfb4c4e016e627d9769e4c9bb0d4fa208e65c26OK
(2)CLUSTER SETSLOT MIGRATING命令的实现
clusterState结构的migrating_slots_to数组记录了当前节点正在迁移至其他节点的槽:
typedef struct clusterState
{
// ...
clusterNode *migrating_slots_to[16384];
// ...
} clusterState;
同理,如果索引i不为NULL,则表示当前节点正在将槽i迁移至目标节点。
在对集群进行重新分片的时候,向源节点发送命令:
CLUSTER SETSLOT <i> MIGRATING <target_id>
可以将源节点clusterState.migrating_slots_to[i]的值设置为target_id所代表节点的clusterNode结构。
5.2 ASKING命令
通过migrating_slots_to这个数组,我们知道当前节点的某个键是否正在迁移。如果是则返回ASK错误。
ASK 16198 127.0.0.1:7003

接到ASK错误的客户端会根据错误提供的IP地址和端口号,转向至正在导入槽的目标节点,然后首先向目标节点发送一个ASKING命令,之后再重新发送原本想要执行的命令。
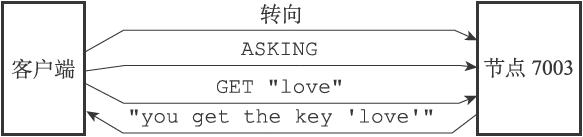
ASKING命令的目的就是打开REDIS_ASKING标识,而且是一次性的打开,意味着使用完后会被关闭。
ASK错误和MOVED错误的区别:
- 相同点:都会导致客户端转向
- 不同点:
- MOVED错误代表槽的负责权已经从一个节点转移到了另一个节点:在客户端收到关于槽i的MOVED错误之后,客户端每次遇到关于槽i的命令请求时,都可以直接将命令请求发送至MOVED错误所指向的节点。
- ASK错误只是两个节点在迁移槽的过程中使用的一种临时措施:在客户端收到关于槽i的ASK错误之后,客户端只会在接下来的一次命令请求中将关于槽i的命令请求发送至ASK错误所指示的节点,但这种转向不会对客户端今后发送关于槽i的命令请求产生任何影响,客户端仍然会将关于槽i的命令请求发送至目前负责处理槽i的节点,除非ASK错误再次出现。
6. 节点的复制与故障转移
和主从服务器的关系非常相似,不过在集群模式下服务器被替换为节点。Redis集群中的节点分为主节点(master)和从节点(slave),其中主节点用于处理槽,而从节点则用于复制某个主节点,并在被复制的主节点下线时,代替下线主节点继续处理命令请求。
6.1 设置从节点
向一个节点发送命令:
CLUSTER REPLICATE <node_id>
可以让接收命令的节点成为node_id所指定节点的从节点,并开始对主节点进行复制,步骤如下:
(1)修改指针指向
接收到该命令的节点首先会在自己的clusterState.nodes字典中找到node_id所对应节点的clusterNode结构,并将自己的clusterState.myself.slaveof指针指向这个结构,以此来记录这个节点正在复制的主节点:
struct clusterNode
{
// ...
// 如果这是一个从节点,那么指向主节点
struct clusterNode *slaveof;
};
(2)修改标识
然后节点会修改自己在clusterState.myself.flags中的属性,关闭原本的REDIS_NODE_MASTER标识,打开REDIS_NODE_SLAVE标识。
(3)调用复制代码
根据clusterState.my-self.slaveof指向的clusterNode结构所保存的IP地址和端口号,对主节点进行复制。因为节点的复制功能和单机Redis服务器的复制功能使用了相同的代码,所以让从节点复制主节点相当于向从节点发送命令SLAVEOF。
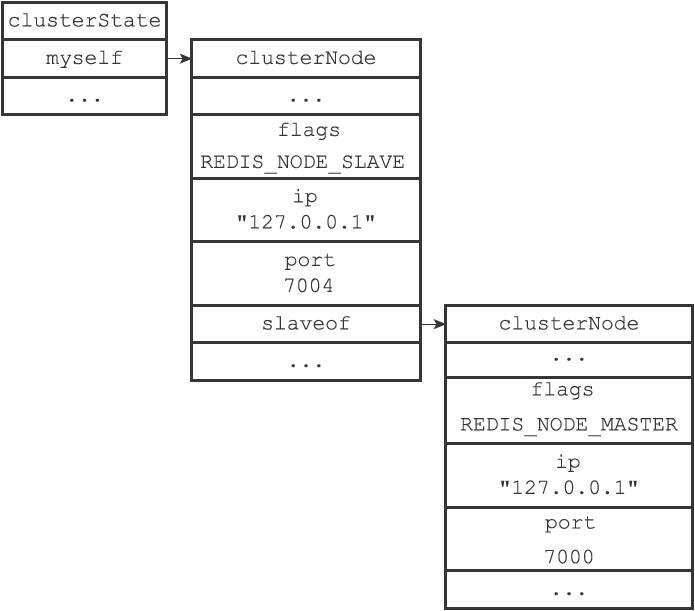
一个节点成为从节点,并开始复制某个主节点这一信息会通过消息发送给集群中的其他节点,最终集群中的所有节点都会知道某个从节点正在复制某个主节点。
集群中的所有节点都会在代表主节点的clusterNode结构的slaves属性和numslaves属性中记录正在复制这个主节点的从节点名单:
struct clusterNode
{
// ...
// 正在复制这个主节点的从节点数量
int numslaves;
// 一个数组
// 每个数组项指向一个正在复制这个主节点的从节点的clusterNode结构
struct clusterNode **slaves;
//....
}
6.2 故障检测
集群中的每个节点都会定期地向集群中的其他节点发送PING消息,如果接收PING消息的节点没有在规定的时间内返回PONG,那么发送PING消息的节点就会将接收PING消息的节点标记为疑似下线(probable fail,PFAIL)
集群中的各个节点会通过互相发送消息的方式来交换集群中各个节点的状态信息,例如某个节点是处于在线状态、疑似下线状态(PFAIL),还是已下线状态(FAIL)。
当一个主节点A通过消息得知主节点B认为主节点C进入了疑似下线状态时,主节点A会在自己的clusterState.nodes字典中找到主节点C所对应的clusterNode结构,并将主节点B的下线报告(failure report)添加到clusterNode结构的fail_reports链表里面:
struct clusterNode
{
// ...
// 一个链表,记录了所有其他节点对该节点的下线报告
list *fail_reports;
// ...
};
如果在一个集群里面,半数以上负责处理槽的主节点都将某个主节点x报告为疑似下线,那么这个主节点x将被标记为已下线(FAIL),将主节点x标记为已下线的节点会向集群广播一条关于主节点x的FAIL消息,所有收到这条FAIL消息的节点都会立即将主节点x标记为已下线。
6.3 故障转移
当一个从节点发现自己正在复制的主节点进入了已下线状态时,从节点将开始对下线主节点进行故障转移,以下是故障转移的执行步骤:
- 从已下线主节点中选出一个从节点
- 从节点执行SLAVEOF no one命令,成为新的主节点
- 新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己。
- 新的主节点向集群广播一条PONG消息,这条PONG消息可以让集群中的其他节点立即知道这个节点已经由从节点变成了主节点。
- 新的主节点开始接收和自己负责处理的槽有关的命令请求,故障转移完成。
7. 消息
集群中的各个节点通过发送和接收消息(message)来进行通信,节点发送的消息主要有以下五种:
- MEET消息:当发送者接到客户端发送的CLUSTER MEET命令时,发送者会向接收者发送MEET消息,请求接收者加入到发送者当前所处的集群里面。
- PING消息:集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个节点,然后对这五个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。
- PONG消息:当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送者确认这条MEET消息或者PING消息已到达,接收者会向发送者返回一条PONG消息。另外,一个节点也可以通过向集群广播自己的PONG消息来让集群中的其他节点立即刷新关于这个节点的认识。
- FAIL消息:当一个主节点A判断另一个主节点B已经进入FAIL状态时,节点A会向集群广播一条关于节点B的FAIL消息,所有收到这条消息的节点都会立即将节点B标记为已下线。
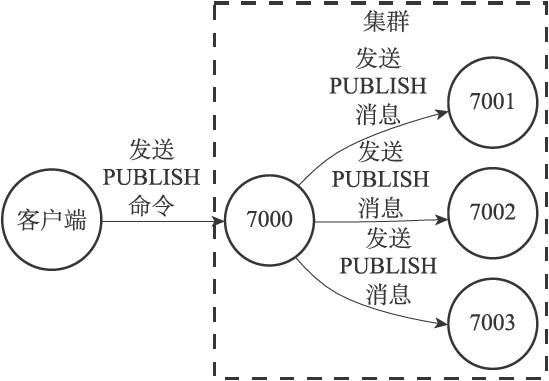
- PUBLISH消息:当节点接收到一个PUBLISH命令时,节点会执行这个命令,并向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会执行相同的PUBLISH命令。
7.1 消息的结构
一条消息由消息头(header)和消息正文(data)组成
每个消息头都由一个cluster.h/clusterMsg结构表示:
// 用来表示集群消息的结构(消息头,header)
typedef struct {
//...
// 消息的长度(包括这个消息头的长度和消息正文的长度)
uint32_t totlen;
// 消息的类型
uint16_t type;
// 消息正文包含的节点信息数量
// 只在发送 MEET 、 PING 和 PONG 这三种 Gossip 协议消息时使用
uint16_t count;
// 消息发送者的配置纪元
uint64_t currentEpoch;
// 如果消息发送者是一个主节点,那么这里记录的是消息发送者的配置纪元
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的配置纪元
uint64_t configEpoch;
// 节点的复制偏移量
uint64_t offset;
// 消息发送者的名字(ID)
char sender[REDIS_CLUSTER_NAMELEN]; /
// 消息发送者目前的槽指派信息
unsigned char myslots[REDIS_CLUSTER_SLOTS/8];
// 如果消息发送者是一个从节点,那么这里记录的是消息发送者正在复制的主节点的名字
// 如果消息发送者是一个主节点,那么这里记录的是 REDIS_NODE_NULL_NAME
// (一个 40 字节长,值全为 0 的字节数组)
char slaveof[REDIS_CLUSTER_NAMELEN];
// 消息发送者的端口号
uint16_t port; /* Sender TCP base port */
// 消息发送者的标识值
uint16_t flags; /* Sender node flags */
// 消息发送者所处集群的状态
unsigned char state; /* Cluster state from the POV of the sender */
// 消息标志
unsigned char mflags[3];
// 消息的正文(或者说,内容)
union clusterMsgData data;
} clusterMsg;
datas属性指向联合cluster.h/clusterMsgData,也就是消息的正文
nion clusterMsgData {
/* PING, MEET and PONG */
struct {
// 每条消息都包含两个 clusterMsgDataGossip 结构
clusterMsgDataGossip gossip[1]; //gossip八卦,小道消息,闲话的意思
} ping;
/* FAIL */
struct {
clusterMsgDataFail about;
} fail;
/* PUBLISH */
struct {
clusterMsgDataPublish msg;
} publish;
//...
};
7.2 消息的实现
(1)Gossip消息的实现
gossip是八卦,小道消息,闲话的意思,专指MEET、PING、PONG这几个消息。这三种消息的正文都由两个cluster.h/clusterMsgDataGossip结构组成。
因为MEET、PING、PONG三种消息都使用相同的消息正文,所以节点通过消息头的type属性来判断一条消息是MEET消息、PING消息还是PONG消息。
每次发送MEET、PING、PONG消息时,发送者都从自己的已知节点列表中随机选出两个节点(可以是主节点或者从节点),并将这两个被选中节点的信息分别保存到两个clusterMsg-DataGossip结构里面。
接受者接收到MEET、PING、PONG消息时,根据保存的两个节点是否认识来选择进行哪种操作:
- 不认识,说明接收者第一次接触被选中节点,则接收者与被选中节点握手
- 认识,根据结构信息进行更新。
比如A节点发送的PING给B,携带了CD两个节点,然后B回复PONG携带了EF两个节点,这样就完成了ABCDEF六个节点的信息交换。每个节点按照周期向不同节点传播PING-PONG信息,就能完成整个集群的状态更新。
(2)FAIL消息的实现
Gossip协议传播速度很慢,而主节点下线的消息需要立即通知给所有人。
FAIL消息的正文由cluster.h/clusterMsgDataFail结构表示,这个结构只包含一个nodename属性,该属性记录了已下线节点的名字:
typedef struct
{
char nodename[REDIS_CLUSTER_NAMELEN];
} clusterMsgDataFail;
因为集群里的所有节点都有一个独一无二的名字,所以FAIL消息里面只需要保存下线节点的名字,接收到消息的节点就可以根据这个名字来判断是哪个节点下线了。
(3)PUBLISH消息的实现
当客户端向集群中的某个节点发送命令:
PUBLISH <channel> <message>
接收到PUBLISH命令的节点不仅会向channel频道发送消息message,它还会向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会向channel频道发送message消息。
也就是说,向集群发送PUBLISH <channel> <message>,会导致集群所有节点都向channel发送message消息。